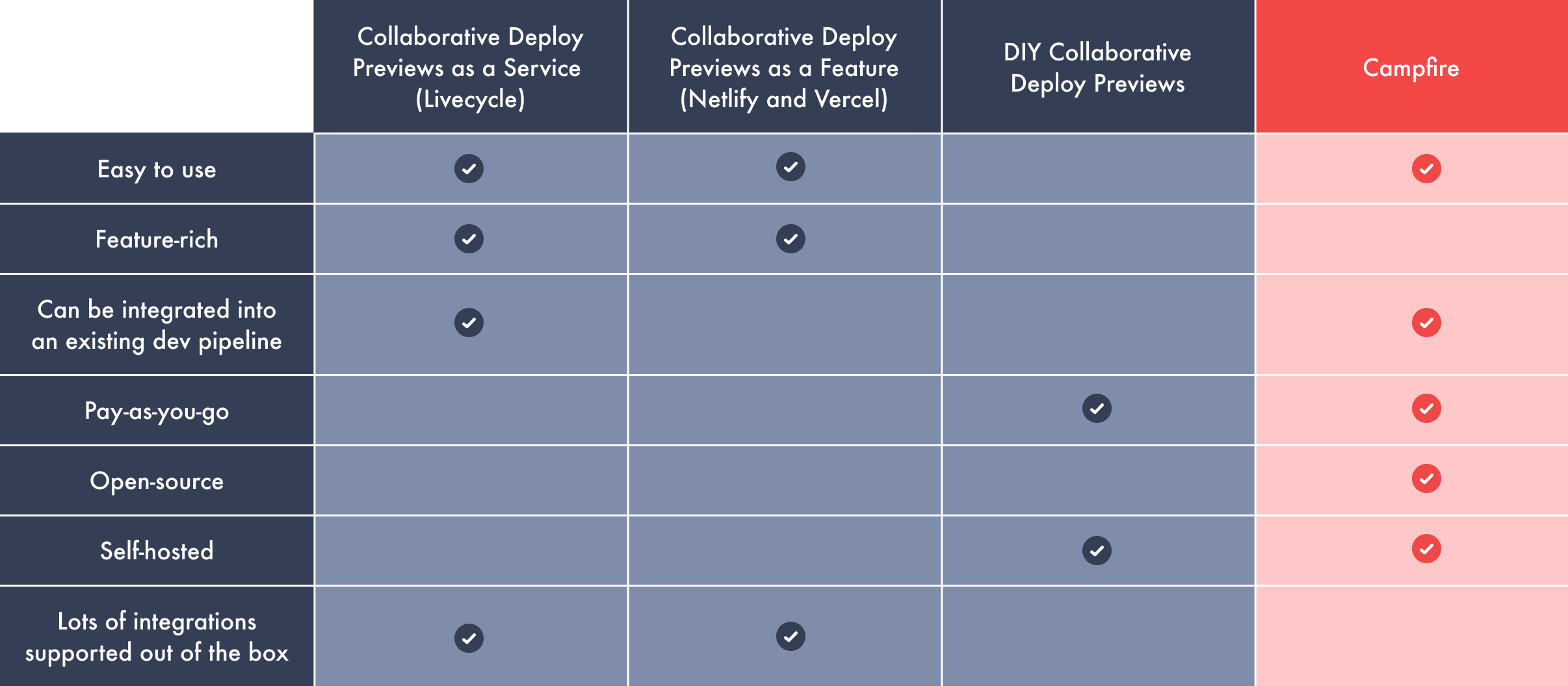
1 - Introduction
Campfire is an open-source, self-hosted, collaborative
deploy-preview solution for containerized, headless frontends.
Much like the way an actual campfire brings people together to
trade stories, Campfire aims to be a central place for
cross-functional teams to visually review and discuss proposed
code changes or bug fixes early in the software development cycle.
Campfire generates a deploy preview for each pull request,
showcasing the latest commit with the proposed changes, which can
be accessed through a public URL. The URL directs users to their
deploy preview, equipped with Campfire's suite of comprehensive
feedback tools.
Integrating a feedback interface directly into the deploy preview
simplifies collaboration between teams and addresses common
bottlenecks that delay project timelines.
1.1 - Terms
In this case study, we'll frequently reference the following
technical terms:
-
Client App - The codebase of the user,
retrieved from the repository when initiating a new pull request
or when a new commit is made to the same pull request.
-
Deploy Preview - The ephemeral infrastructure
provisioned to host a live preview of the Client App for each
pull request. Also known as ephemeral environments, preview
environments, or preview apps.
-
Feedback Interface - A relatively new
component of some deploy preview solutions, which provides an
overlay for user collaboration and feedback on the previewed
changes.
2 - The Problem
In the early days of web development, software engineers often
made live changes directly on production servers, a risky practice
that could easily break the website or service.
As the industry matured, developers began adopting version control
systems like Git and SVN to better manage and track code changes.
However, these systems did not solve the problem of testing
changes in a controlled environment before production deployment.
1
2
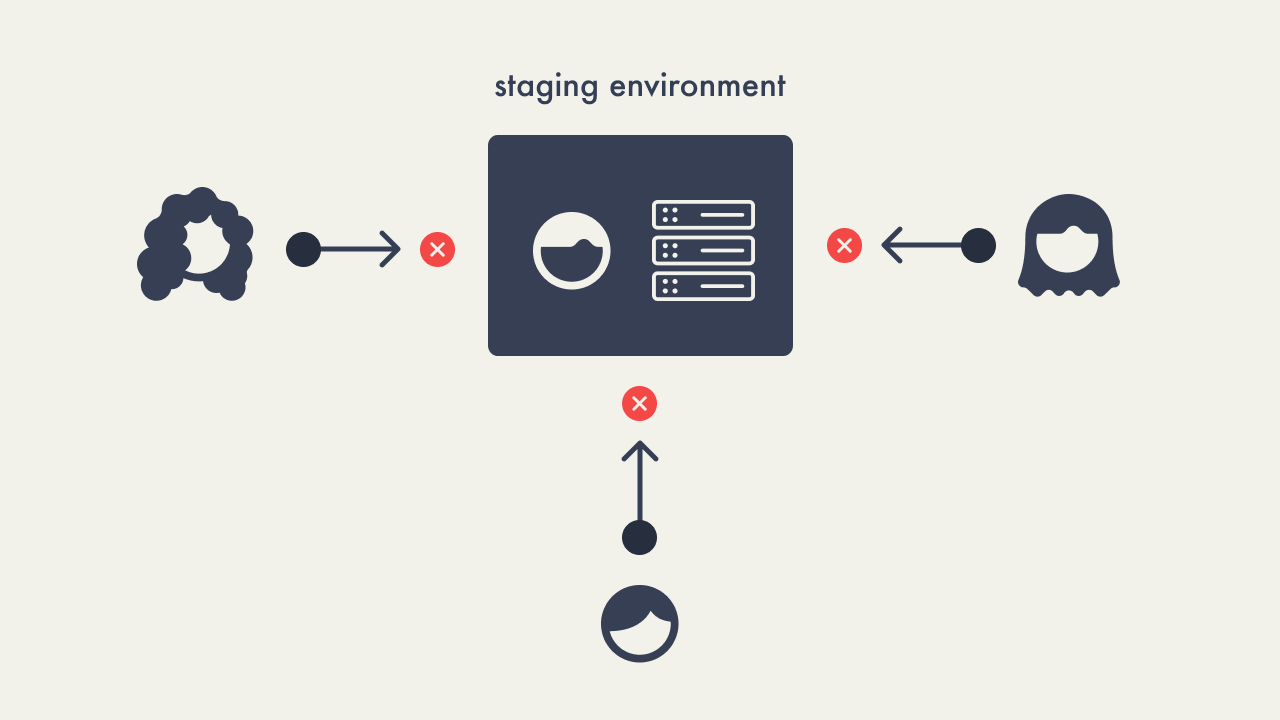
The rise of agile development and continuous
integration/continuous deployment (CI/CD) practices led to the
adoption of staging environments. These environments allowed teams
to test code in settings that closely mirrored their production
environment, enabling them to identify and fix bugs without
affecting the live application. Despite the benefits, staging
environments introduced significant bottlenecks. Multiple
developers often pushed their changes to a single staging
environment simultaneously, leading to conflicts and resource
contention. This not only caused delays and increased security
risks but also led to bugs and higher operational costs.
3
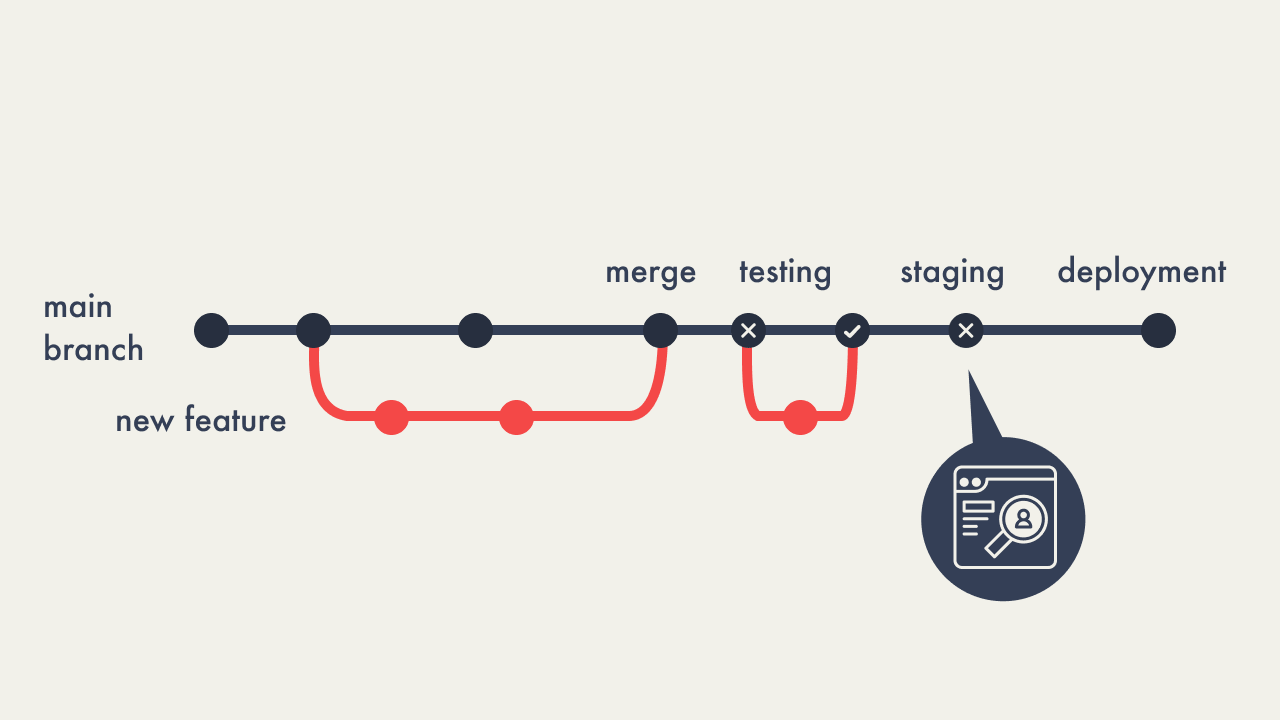
The process of resolving bugs found in staging involves several
structured steps, especially when using tools like GitHub:
-
Branch Creation - Developers create a new
branch from the main codebase, allowing them to address bugs
without impacting the stable production version.
-
Commit Changes - Necessary fixes are made and
committed to the branch, with detailed commit messages
explaining the changes.
-
Push to Repository - The branch is then pushed
to the remote repository on GitHub.
-
Create Pull Request - A pull request is opened
against the main branch for merging the fixes and facilitating
code review.
-
Code Review and Approval - The pull request is
reviewed by team members who may suggest or request changes.
-
Merge and Deploy to Staging - After approval,
the changes are merged and deployed to the staging environment
to verify the bug fix.
-
Testing in Staging - The application is tested
in staging to ensure the fix is effective and no new issues have
arisen.
-
Push to Production - Once confirmed, the
changes are deployed to production.
-
Monitoring - Post-deployment the application is
monitored for any unexpected issues.
If bugs are detected during staging tests, the process from branch
creation to staging deployment may need to be repeated to ensure
all issues are thoroughly addressed.
456
Historically, non-engineering team members such as UI designers,
QA testers, marketers, and product managers had limited
opportunities to view and provide feedback on proposed changes
until late in the development process. Often, they only saw these
changes when they were moved to the staging or production
environments.
This delay not only prevented timely feedback that could influence
design and functionality but also excluded these key stakeholders
from early stages of project discussions. Additionally, the lack
of a dedicated feedback mechanism in earlier development stages
meant that their insights, which could significantly impact user
experience and product success, were often underutilized or
solicited too late to make meaningful adjustments without
time-consuming revisions.
7
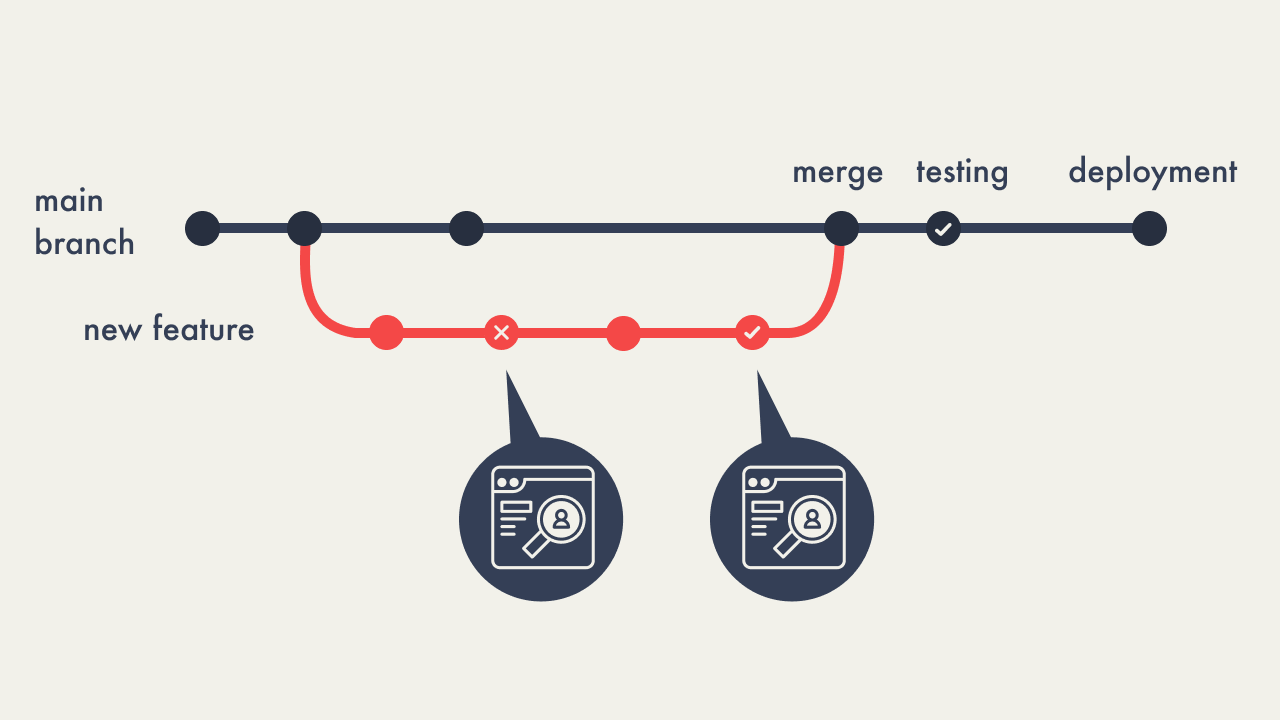
2.1 - Deploy Previews
Deploy previews were introduced as a solution to streamline the
code review process, allowing engineers to view changes earlier in
the development process without the need to manually pull down
code or wait for access to a staging environment. This drastically
shortened the cycle between identifying bugs and deploying fixes,
enabling faster iterations and more efficient development.
Deploy previews also provided an accessible platform for
non-engineering team members to view proposed changes. This
expanded the review process to a broader group of stakeholders and
enabled collaboration across different teams. Despite their
effectiveness in demonstrating code changes, deploy previews
initially lacked integrated tools for submitting feedback directly
within the previews.
2.2 - Limitations of Deploy Previews
While deploy previews were adept at showcasing code changes, they
lacked an interface to provide feedback to the proposed changes
within the same application. This forced users to use third-party
tools to provide feedback on the proposed changes, like Slack and
GitHub for comments or Loom and Zight (formerly CloudApp) for
screen recordings, or Zoom for synchronous video calls. The
absence of a unified feedback interface often led to scattered
comments across many different platforms, complicating the
aggregation and tracking of feedback, and often causing the
context to be lost.
Comments made across multiple different platforms led to
disjointed communication, complicating the feedback process. Even
if developers consolidated discussions on GitHub, non-engineering
team members, such as project managers, designers, and QA
personnel, were often left out of the loop. They often don’t have
GitHub accounts and would seek a straightforward way to comment on
visual changes. Not having a built-in, accessible feedback system
in deploy previews made it harder to collaborate and quickly fix
problems.
8

3 - Existing Solutions
Several solutions have recently been developed to add a
communication layer to deploy previews, making collaboration more
accessible for non-technical team members. Services like Netlify
Drawer, Vercel Comments, and Livecycle have attempted to bridge
this gap by offering built-in tools for capturing feedback when
the user is viewing proposed changes. Each of these services
presents different tradeoffs, particularly in terms of hosting
options, whether they are open-source, and the ease of setup and
use.
3.1 - Deploy Previews as a Feature
Netlify and Vercel integrate deploy previews within their broader
suite of services, providing a production-like view of changes
pre-deployment. Netlify, primarily a host for static sites and
supports Jamstack projects, includes Netlify Drawer as a feature
available for their deploy previews. Similarly, Vercel is tailored
for frontend frameworks like Next.js, incorporating Vercel
Comments into its regular services, so that non-engineering team
members have the ability to provide feedback on their team’s
deploy previews.
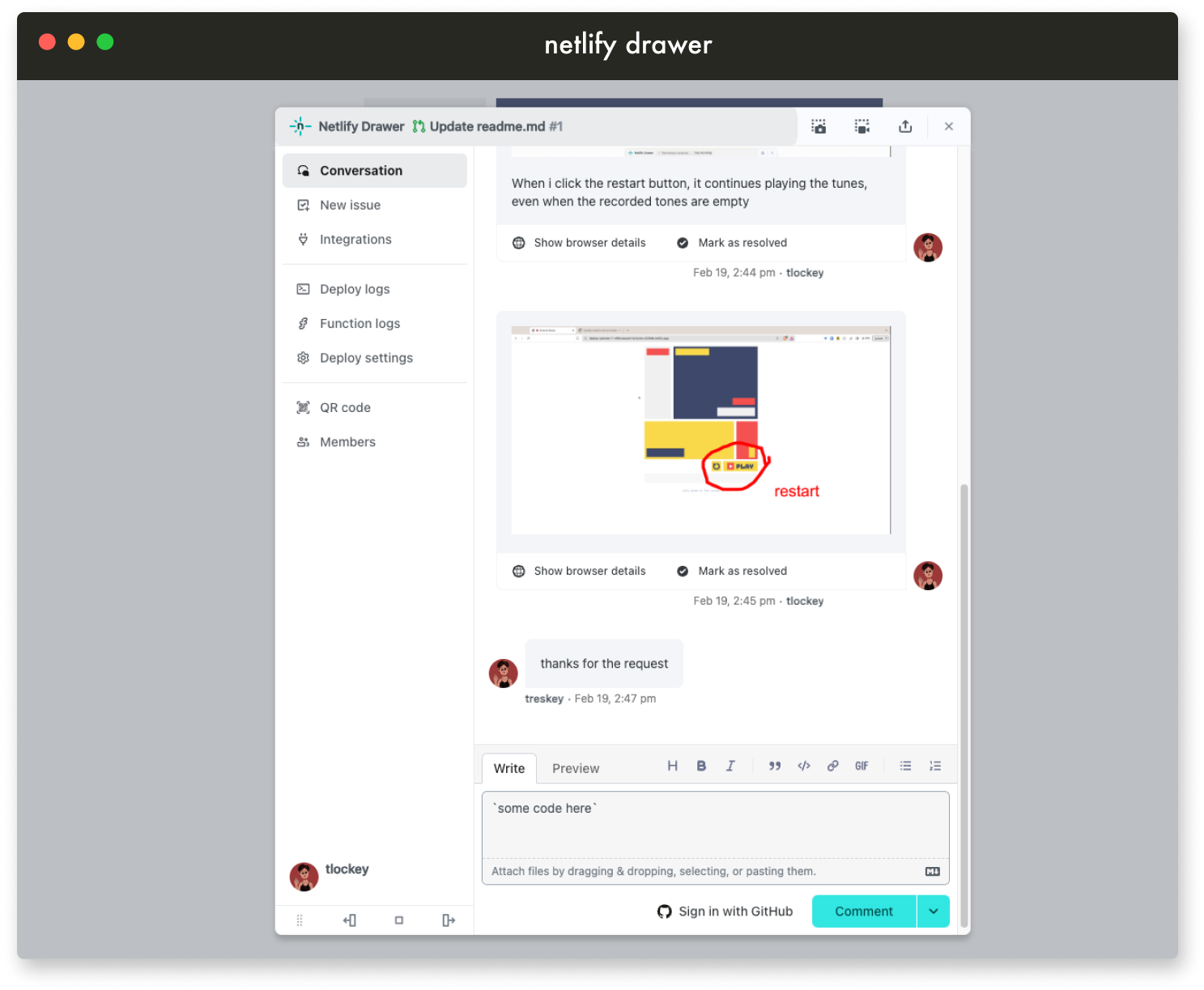
Netlify Drawer enhances Netlify’s deploy previews with a feedback
toolbar for screenshots, recordings, and comments. The Drawer
comment feature allows for synchronizing feedback between the
deploy preview and GitHub. Comments can be posted by Netlify
Drawer’s bot if the user does not have a GitHub account.. This
integration includes the user’s browser metadata in comments,
providing context in order to make it easier for developers to
recreate and fix any potential bugs.
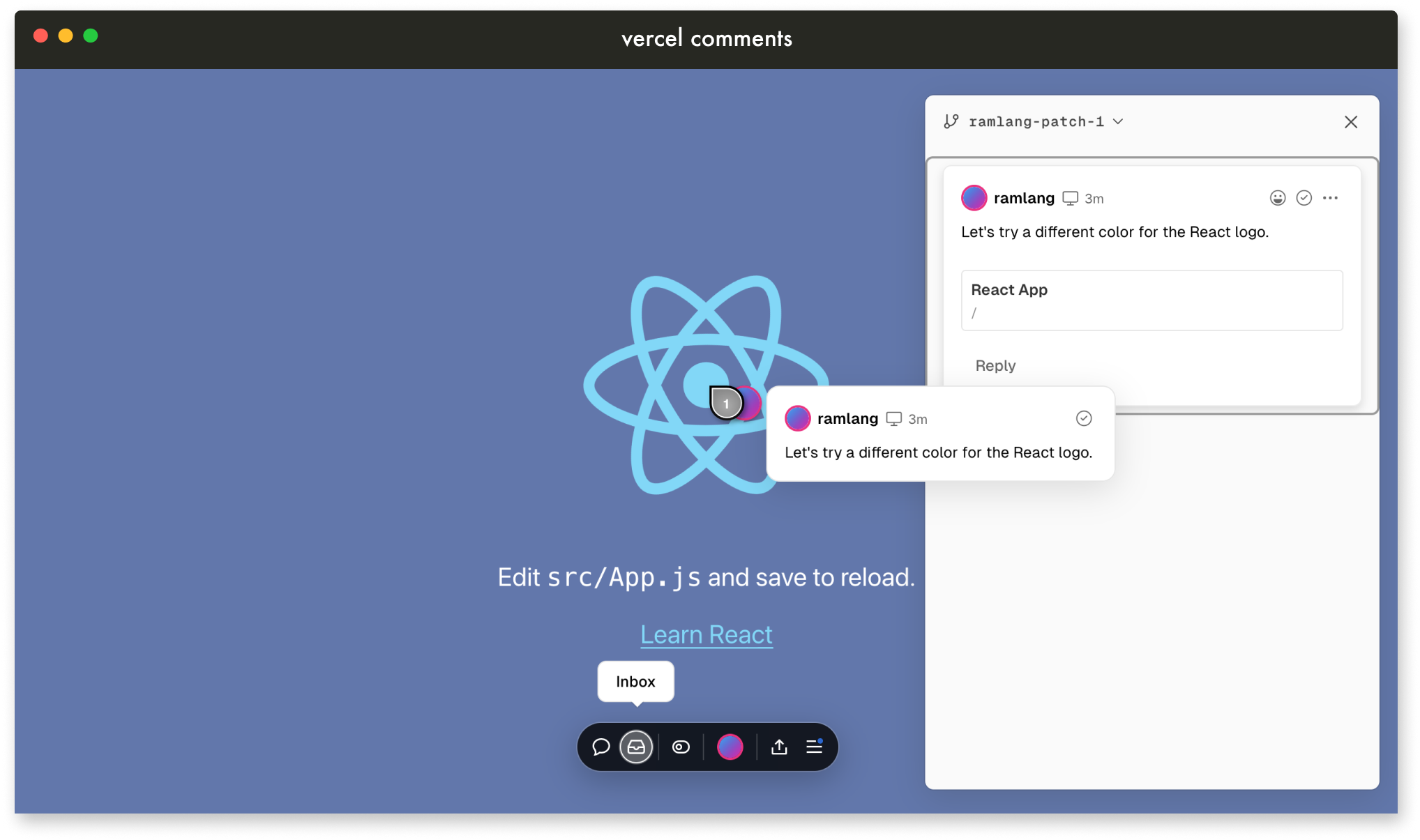
Vercel’s Comments leverage Liveblocks, a third-party real-time
collaboration tool, allowing users to attach comments directly to
UI elements. This integration improves feedback by allowing more
interactive and detailed discussions. Unlike Netlify, Vercel syncs
their comments with Slack rather than GitHub.
These services, while feature-rich, come with the caveat of
requiring full application hosting on their platforms, limiting
flexibility for teams who prefer independent control over their
deployment.
3.2 - Livecycle
Livecycle's preview environments are the core of their project
offering. Livecycle offers a unique combination of deploy previews
and collaborative tools through its products, Preevy and a product
also named Livecycle. Preevy manages preview environments via
CI/CD workflows or an SDK for external hosting. Livecycle
integrates a feedback interface enabling commenting, HTML/CSS
suggestions, and visual edit comparisons. Additionally, Livecycle
provides debugging tools like screen size adjustments, rudimentary
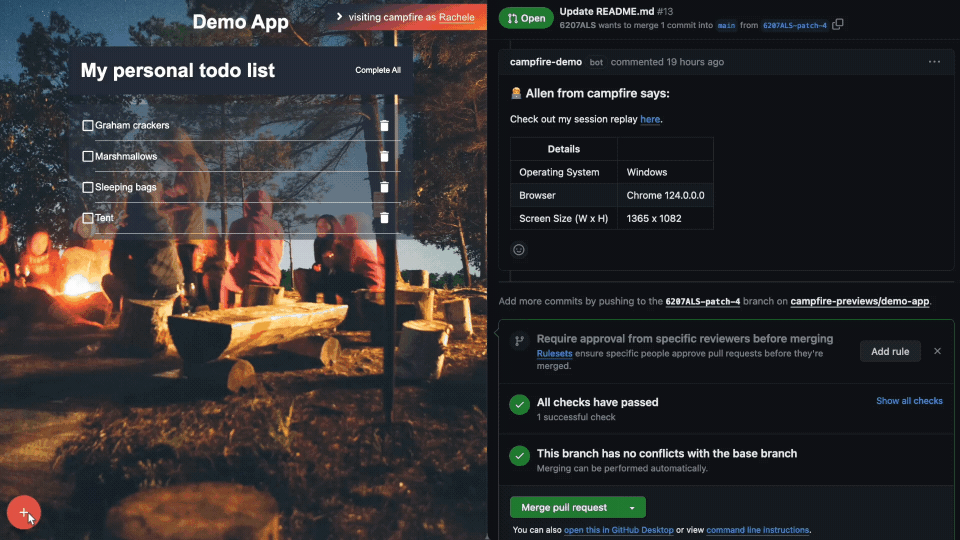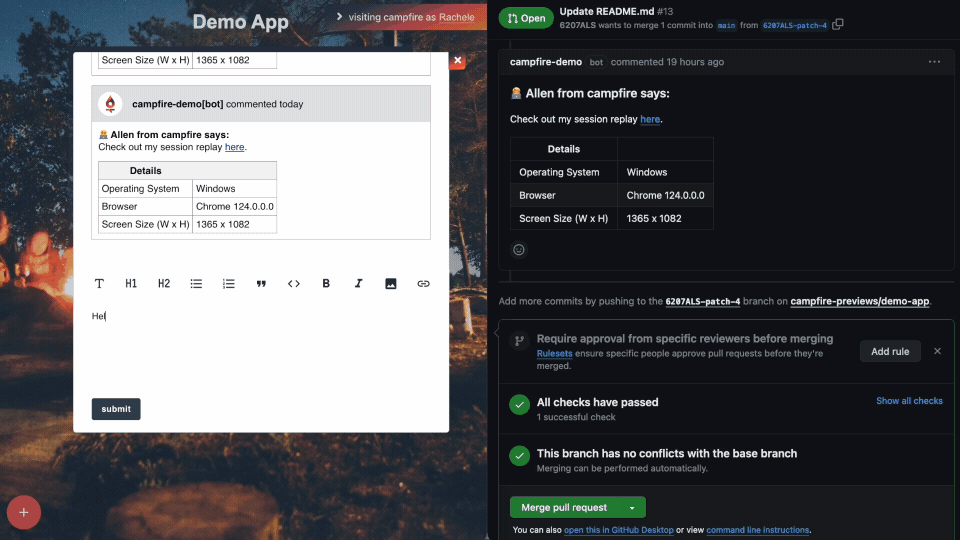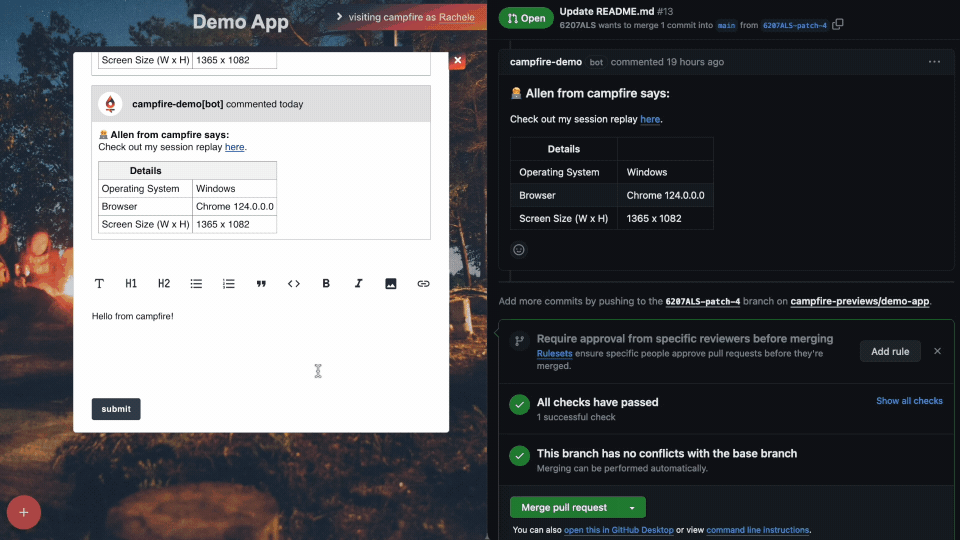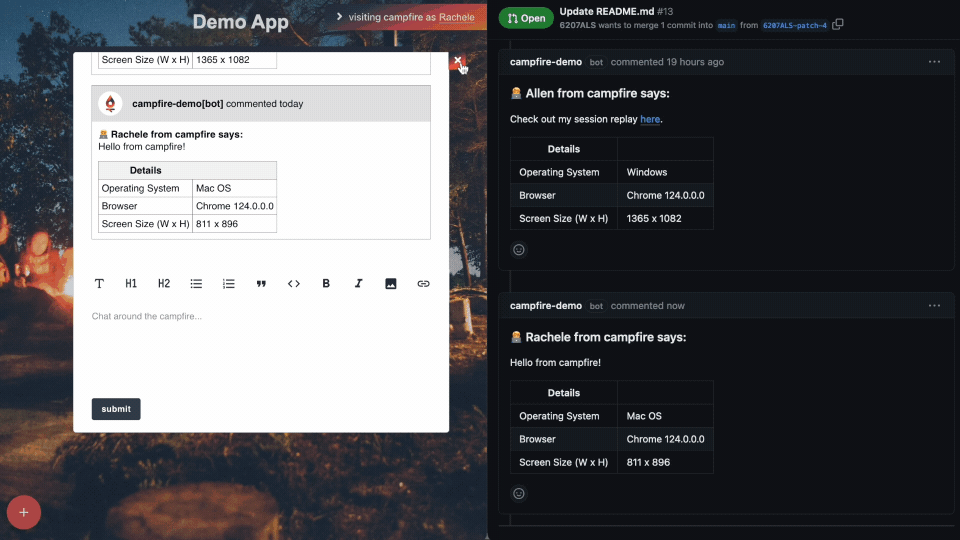
dev tools, and console access. Its session replay feature
automatically captures user interactions within the preview
environment, offering a replayable video that begins recording
from the moment the user visits the deploy preview.
3.3 - DIY
A custom-built deploy preview solution offers a team complete
control over their development and review process. This building
process can be divided into two main parts: the deploy preview
functionality and the feedback system, together encompassing up to
40 steps or more.
Implementing such a custom solution requires dedicated teams of
engineers, integration with existing tools, and ongoing
maintenance. The complexity and resource demands can make it
overwhelming and impractical for organizations lacking extensive
technical expertise in automating workflows and managing cloud
service resources.

4 - Introducing Campfire
Campfire removes the trouble of building a DIY solution from
scratch while still providing organizations control over their
data, and allowing integration into an existing CI/CD pipeline.
Our primary goal was to design a feedback interface that
integrates seamlessly with the deploy preview, ensuring
stakeholders can provide feedback without switching contexts. This
interface supports comments and session replays and allows the
capture of contextual data to enhance understanding. Although not
as feature and integration-rich as solutions like Livecycle,
Netlify Drawer, and Vercel, Campfire offers an open-source
alternative with comments that sync to a GitHub pull request and
the ability to record sessions, providing context-rich feedback
directly within the deploy preview.
4.1 - Who Campfire is For
Campfire is designed to support front-end applications that meet
the following criteria:
- Hosted on GitHub
- Contain a Dockerfile
-
Operate independently of a backend or interact with an external
backend via APIs.
- Targeted towards small or early-stage teams
Campfire is not designed to support the following types of
applications:
- Hosted on GitLab or other developer platforms
-
Require a container image to be generated from source code
- Monolithic architecture
- Multi-container applications
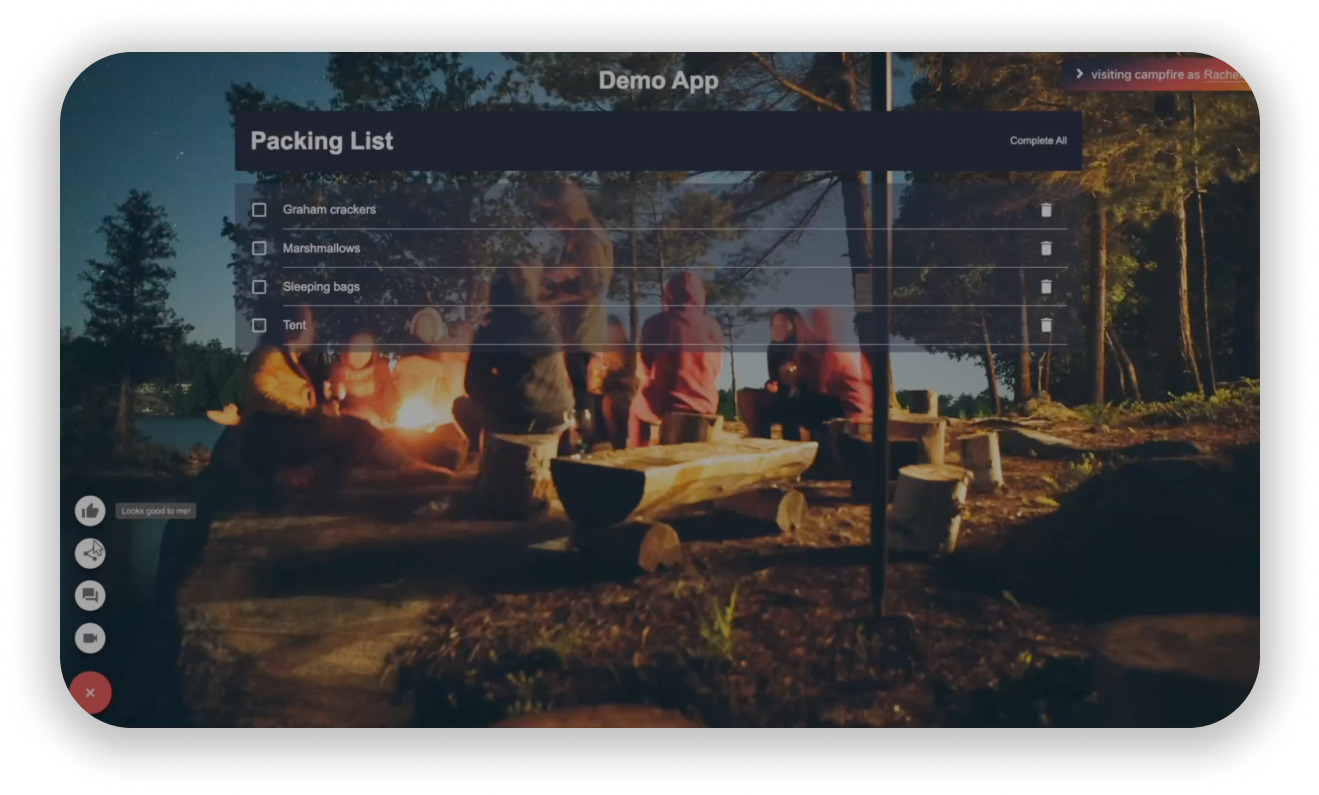
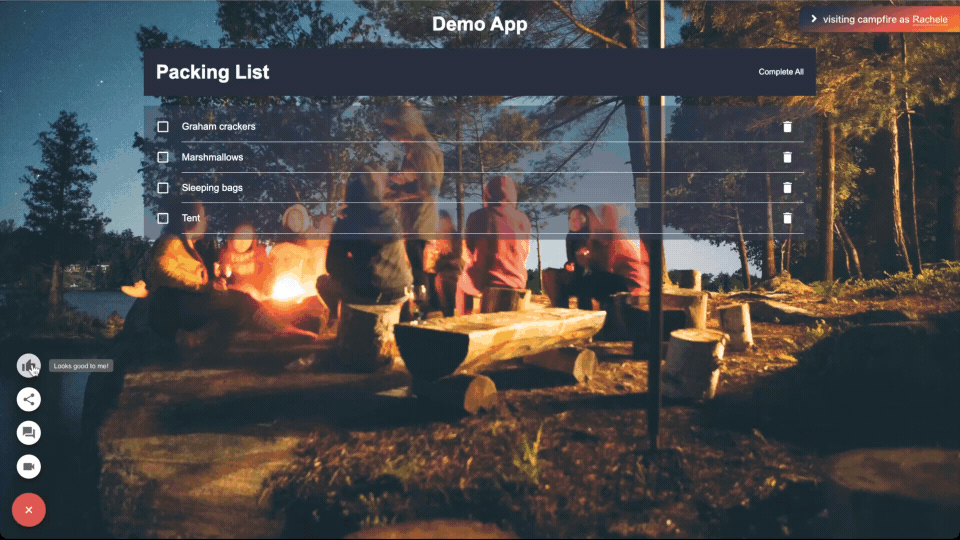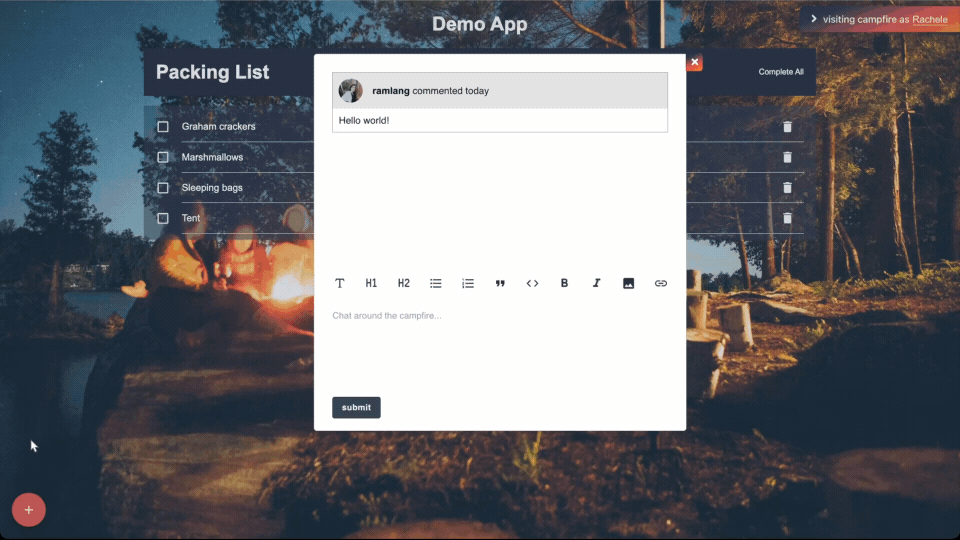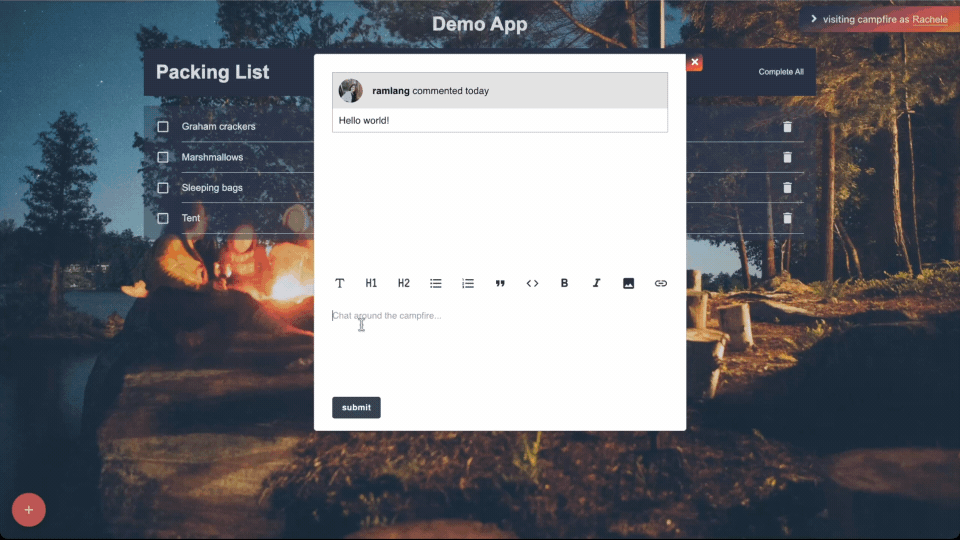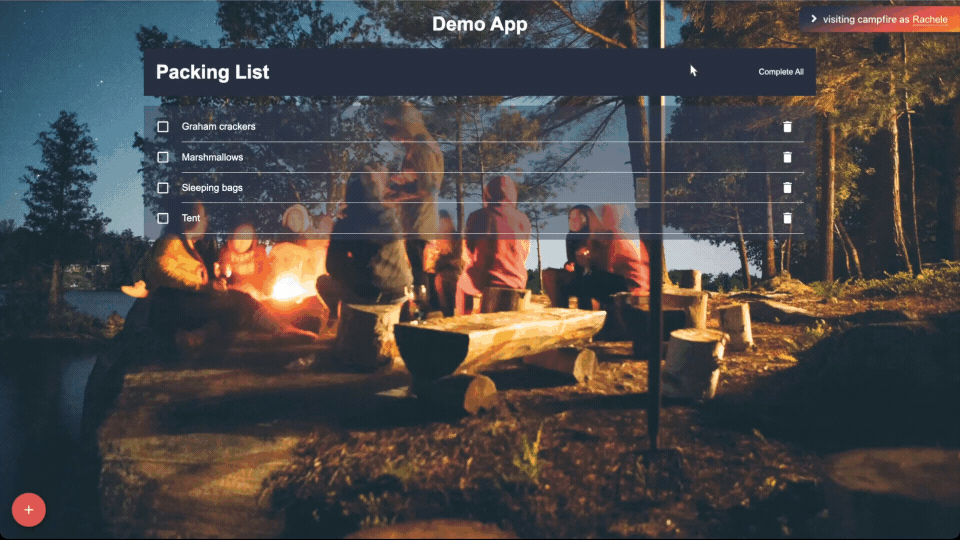
4.2 - Campfire Features
CLI tool to simplify the installation and configuration of Campfire:
Integration with GitHub automates the creation, update, and
dismantling of preview environments:
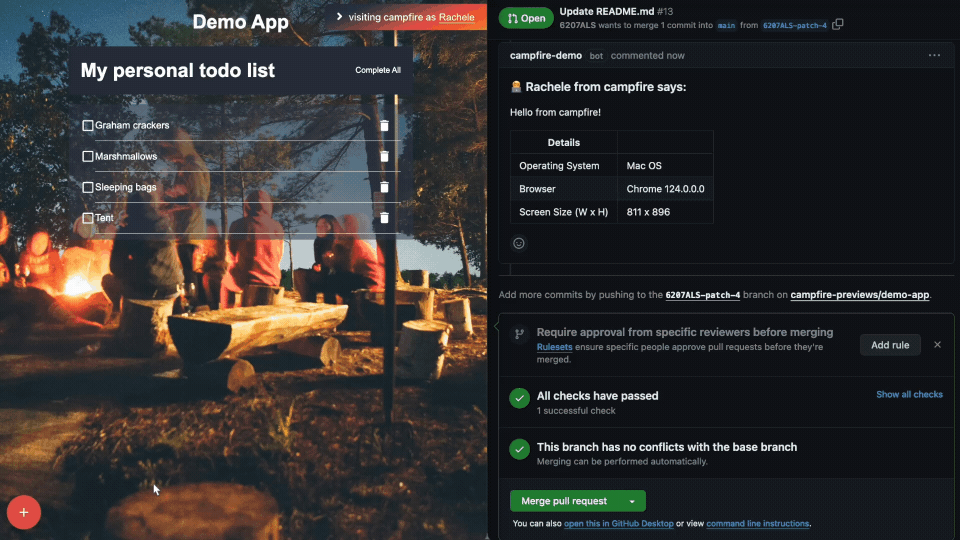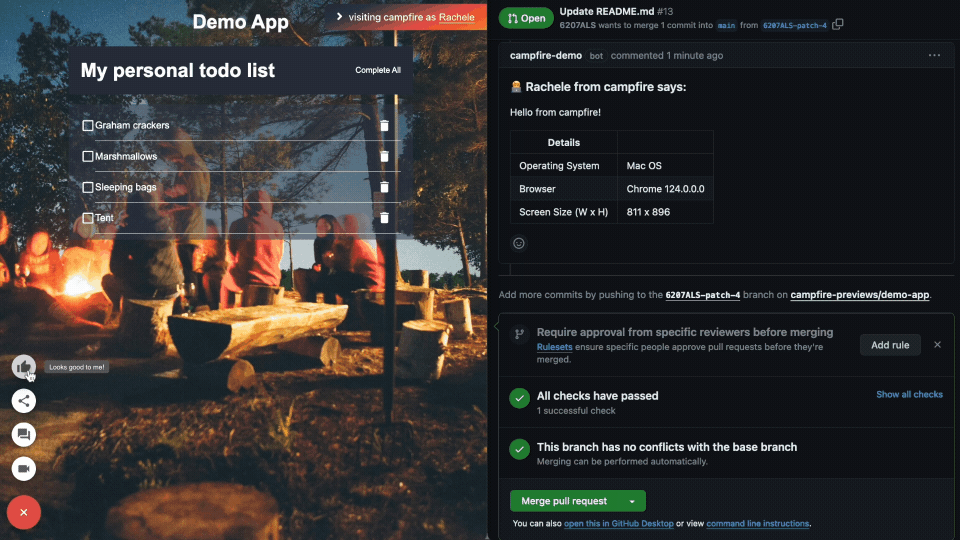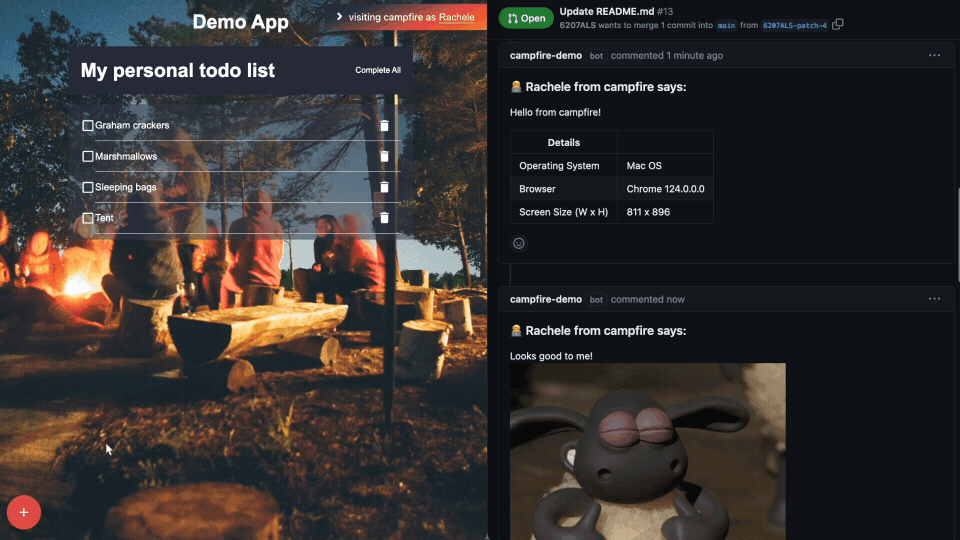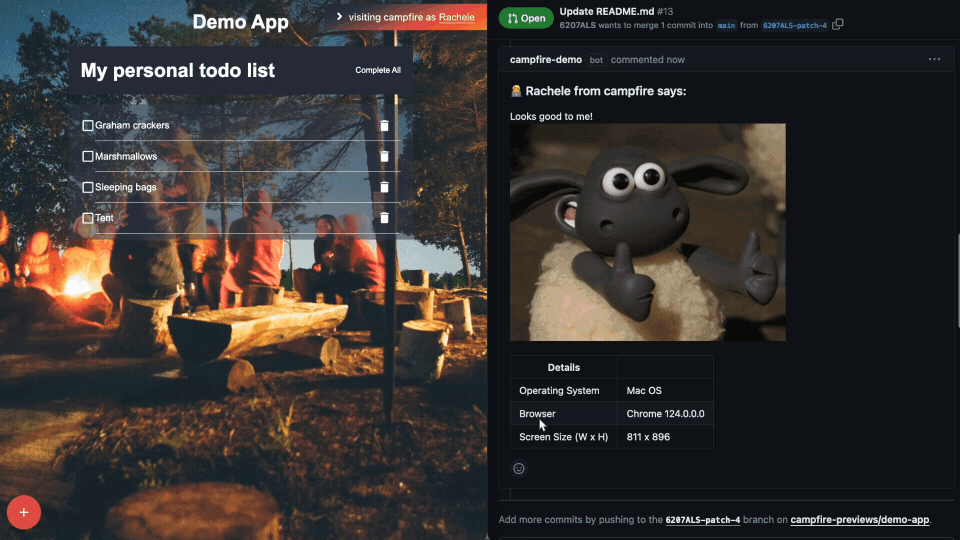
Looks Good to Me (LGTM) Button to quickly approve changes with a
simple acknowledgment (and confetti):
Comments provide feedback directly on the deploy preview and sync
with the GitHub pull request:
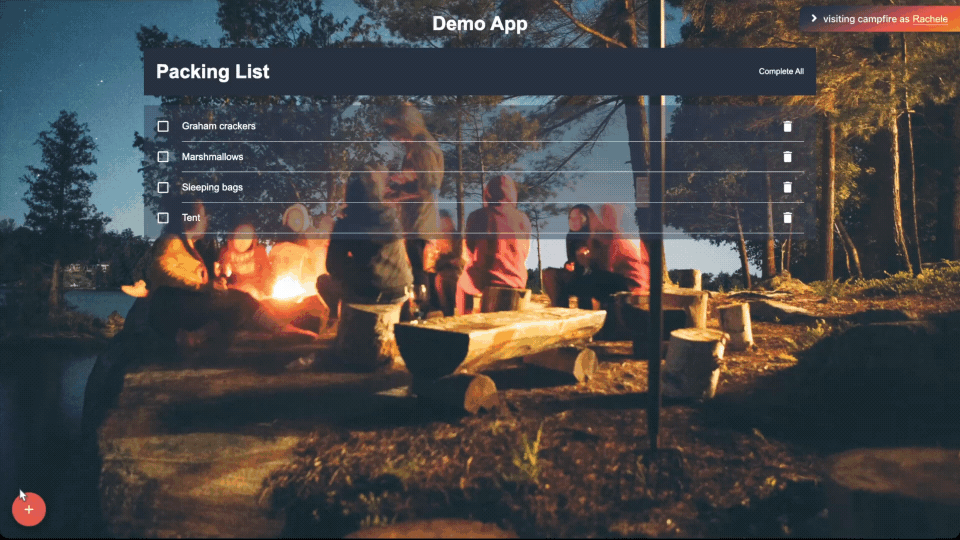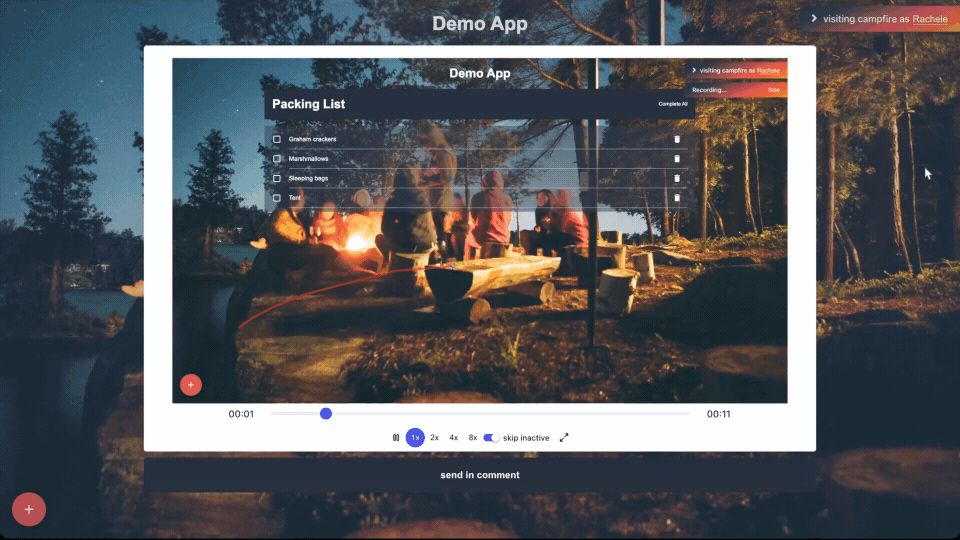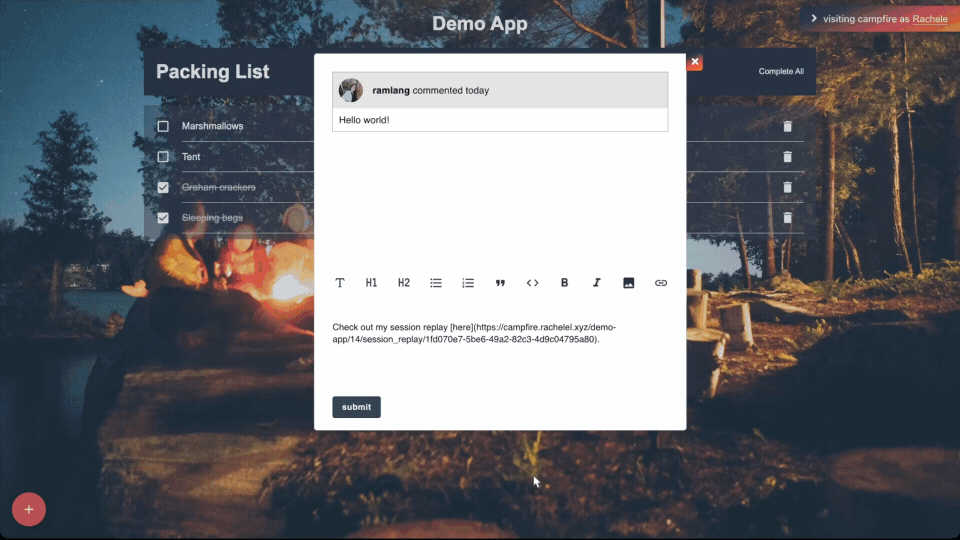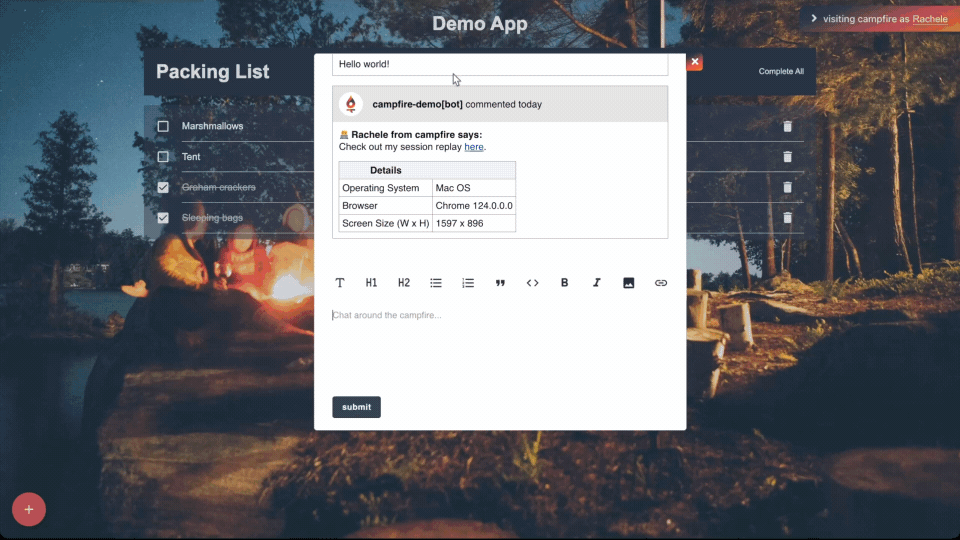
Session Replay to capture user interactions in real-time to
demonstrate issues:
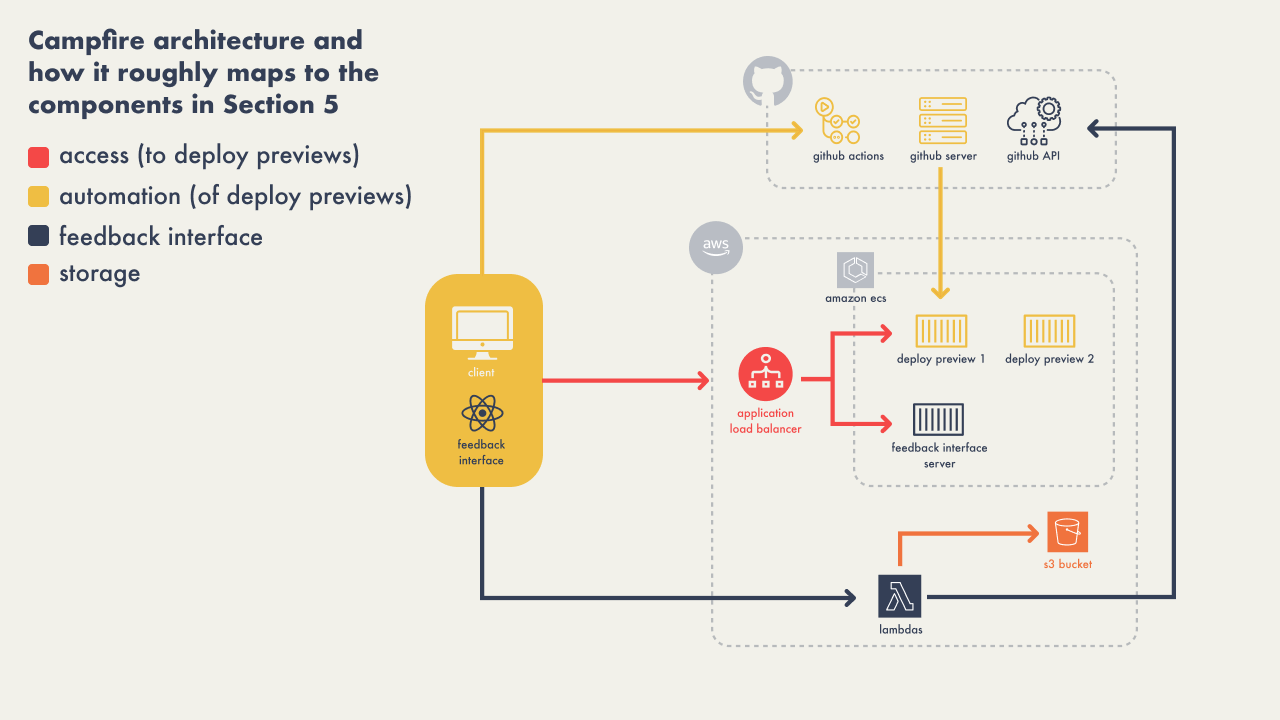
5 - Developing Campfire
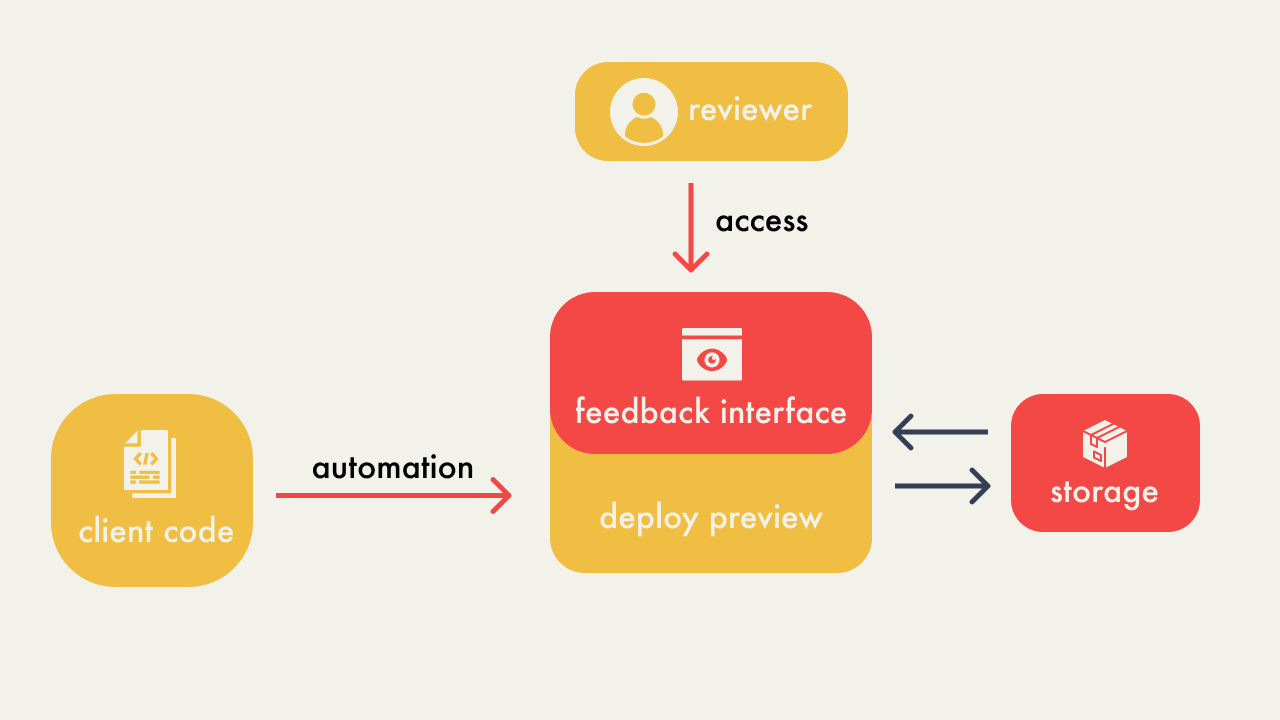
In order to build Campfire, we identified four components of a
collaborative deploy preview solution:
-
Automation - An automated process to generate
deploy previews for each new pull request, or new commit to an
existing pull-request.
-
Access - A reliable and straightforward method
for users to access these previews to view and interact with the
proposed changes.
-
Feedback Interface - An integrated feedback
mechanism within the deploy preview to collect and display
feedback, allowing stakeholders to comment and discuss directly
on the preview.
-
Data Storage - A place to store and manage
Campfire’s data.
This diagram is an overview of all the responsibilities we
described and how they interact with each other:
5.1 - Automating Deploy Previews
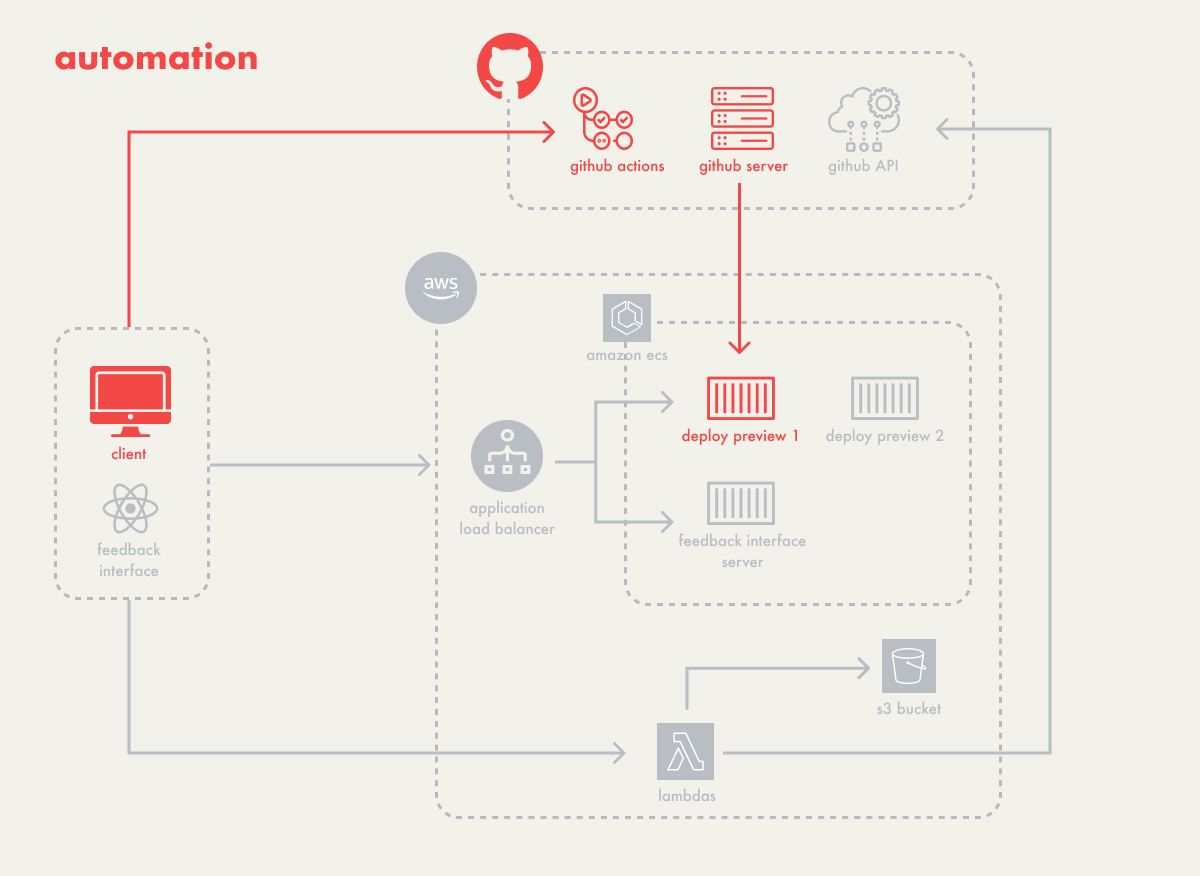
Campfire’s architecture starts with the automatic deployment of
deploy previews, which are generated for each pull request and
hosted temporarily until the pull request is closed. We faced two
primary decisions in this area:
-
How to automatically trigger a deployment when a pull request is
made?
- How to host the client application once deployed?
5.1.1 Automatically Triggering Deployment
We initially considered using webhooks to trigger a self-hosted
endpoint whenever a pull request was created by the user. However,
this required deploying a dedicated service to handle webhook
events, which would involve additional resources being provisioned
on the user’s AWS account.
We opted instead for GitHub Actions, a CI/CD platform that offers
the flexibility of using either self-hosted or GitHub-hosted
runners to automate workflows. This approach eliminates the need
to manage separate resources for webhook responses. GitHub Actions
automatically provisions an environment to execute our defined
workflows, which handle tasks such as authenticating cloud
services, spinning up the necessary resources for the deploy
preview, and posting the preview URL back to the pull request.
Additionally, GitHub Actions manages the lifecycle of the runners,
ensuring they shut down and clean up resources after execution.
This efficiency and integration led us to choose GitHub Actions
for automating the deployment of deploy previews. Consequently, a
fundamental requirement for using Campfire is that the user’s
application must be hosted on GitHub; therefore, we are currently
unable to support users on other platforms like GitLab.
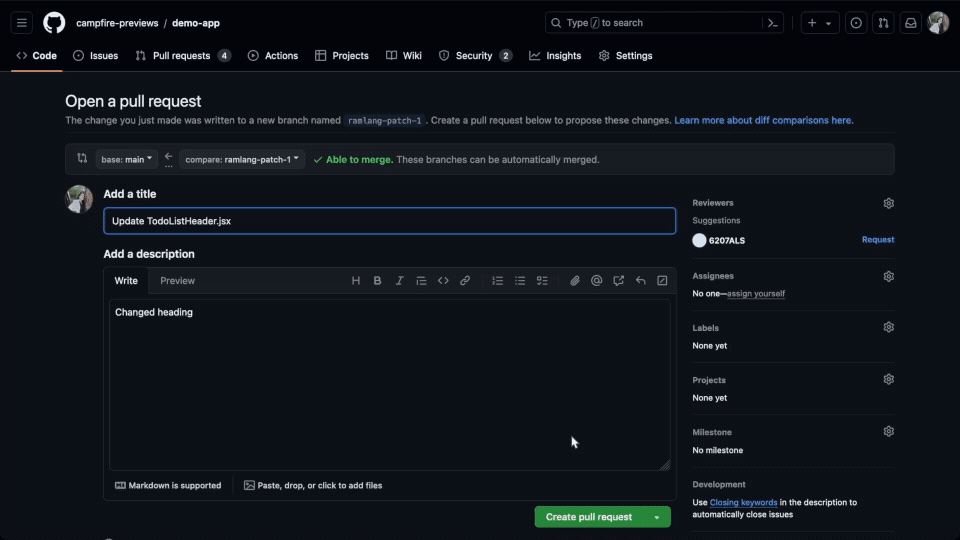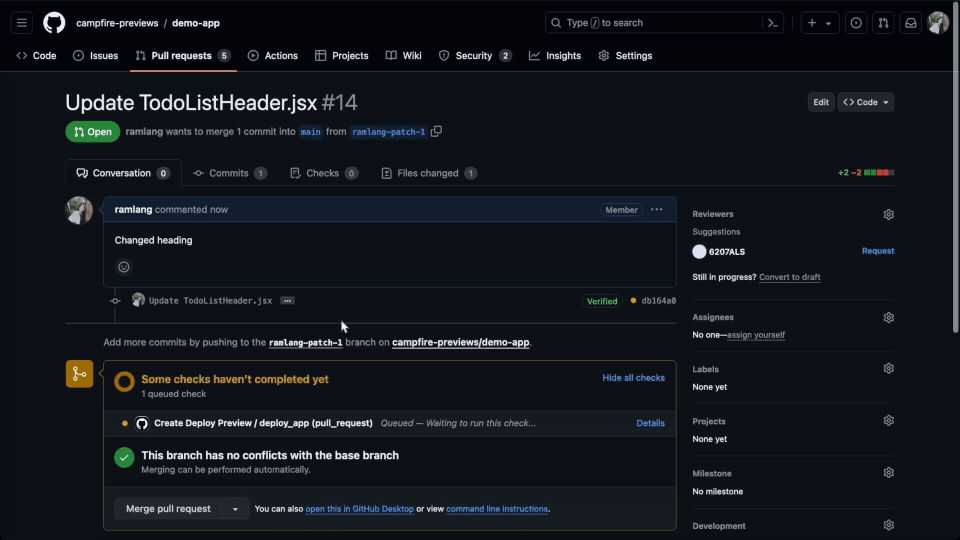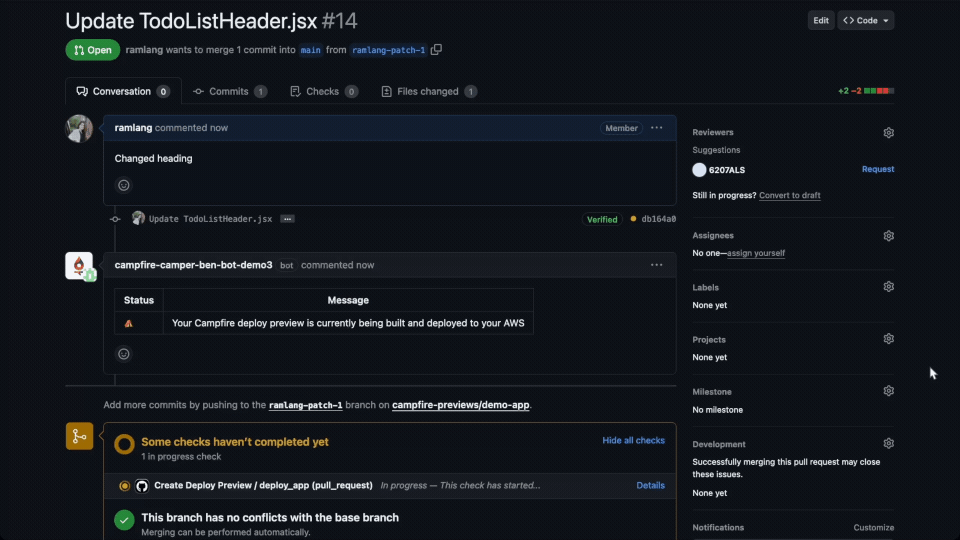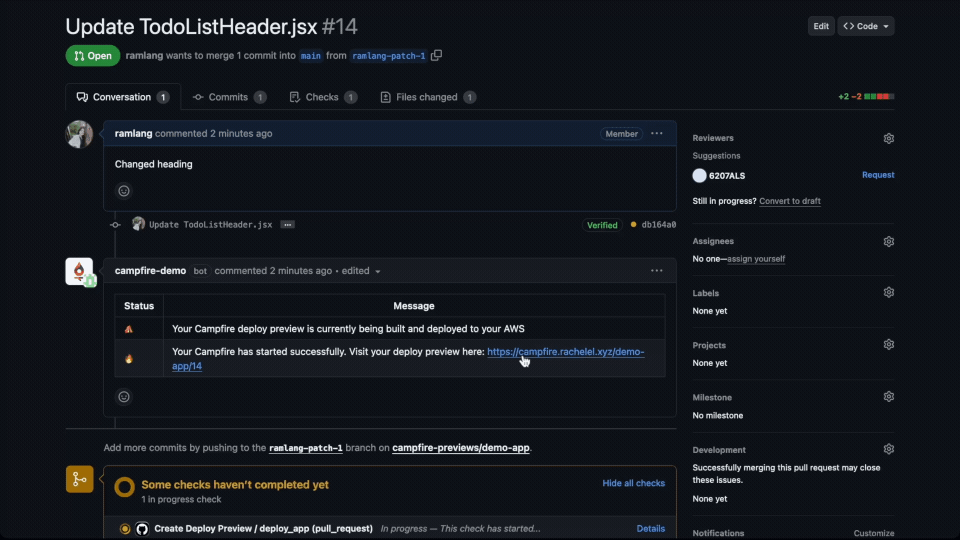
5.1.2 Hosting the Client’s Application
The next step involved selecting a service to temporarily host the
client application. To accommodate a diverse range of applications
and simplify the deployment process, Campfire chose to support
containerized applications. Containerization packages an
application with its dependencies and configurations into a
standardized unit, or container, ensuring it runs consistently
across any environment.
Ensuring that the client application behaves the same way locally
as it does once deployed minimizes bugs related to cross-platform
compatibility issues. By focusing on containerized applications,
we enhance the likelihood of successful deployments regardless of
the specific setup or technology stack of the application.
The use of containers required a way to manage their life cycles –
deploying, updating, and terminating containers as pull requests
are opened, updated, or closed. Container orchestration services
provide many features in addition to managing the lifecycle of
containers, including automated scaling and high availability.
Without container orchestration services, manual management of
container lifecycles and scaling would be required, introducing
complexity and potential for error.
We selected AWS Elastic Container Service (ECS) because it
simplifies container orchestration and easily integrates with
other AWS services such as the application load balancer used in
Campfire. ECS automates the deployment, scaling, and monitoring of
containers, allowing us to deliver stable and consistent deploy
previews without the burden of managing the orchestration layer
ourselves.
While other solutions like Elastic Kubernetes Service (EKS) and
Docker Swarm offer more control and flexibility in managing
containers, they require deep knowledge of their ecosystems and
are feature-rich, which can be excessive for our needs. Given that
Campfire requires orchestration for just a single container per
pull request, the simpler and less complex ECS is more appropriate
than the more powerful but complex alternatives like EKS and
Docker Swarm.
5.2 - Accessing Deploy Previews
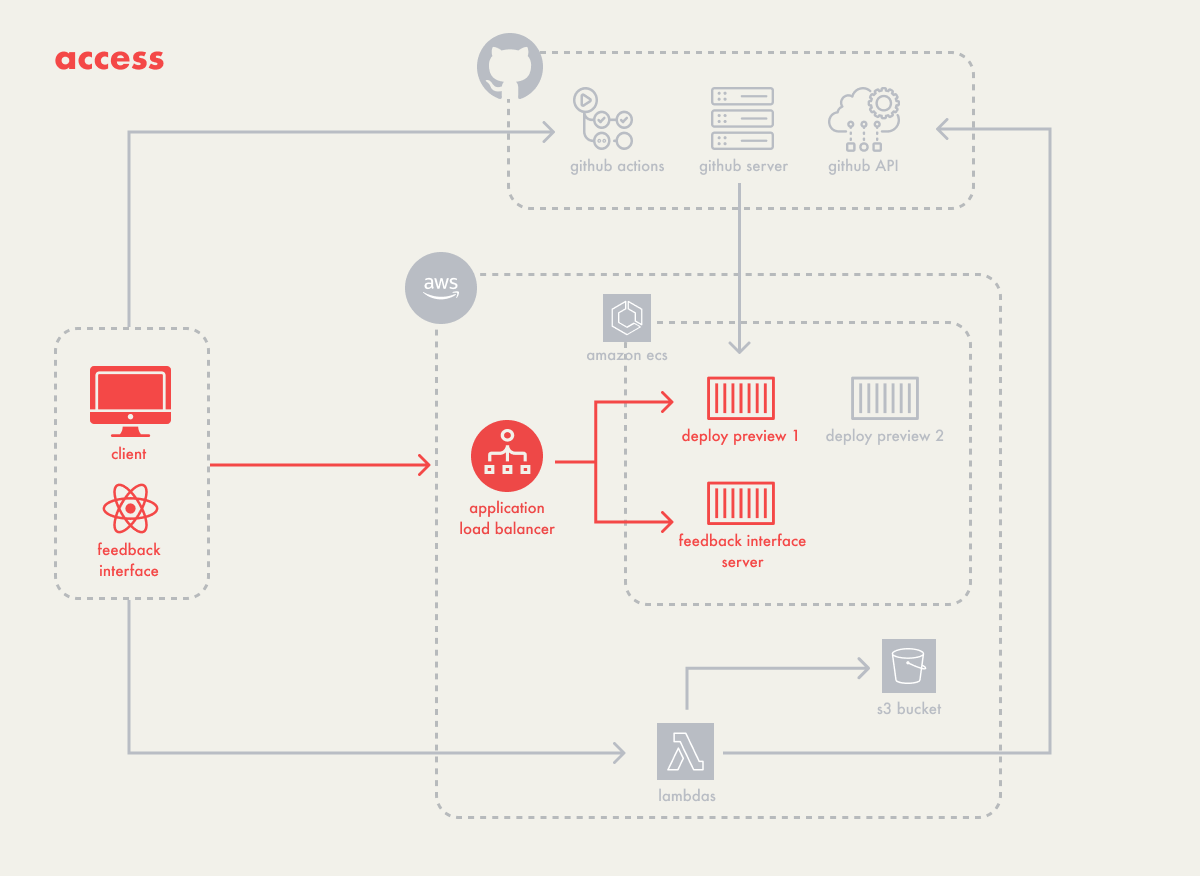
Access to each deploy preview was the next step for Campfire.
Within our setup with AWS ECS, each deploy preview operates as a
separate task. A task is a running instance of a containerized
application, specified by its CPU, memory, and network settings in
a task definition. Each task is automatically assigned a public IP
that can be used to access the running instance. These public IPs
can change if a task is restarted due to updates, configuration
changes, or scaling operations. To manage the dynamic nature of
public IPs, we implemented an application load balancer.
Generally, a load balancer distributes incoming network traffic
across multiple servers. For Campfire, which hosts a single
instance of a client’s application in a container, the load
balancer functions more like a router. It efficiently channels
incoming traffic to our preview tasks, using listeners to direct
traffic according to predefined Campfire rules.
The traffic is then routed through these rules to target groups,
which are collections that map to specific ECS tasks, regardless
of their currently assigned IP addresses. Having an application
load balancer means access to Campfire’s deploy previews remains
stable and continuous, even when individual tasks undergo IP
changes due to restarts.
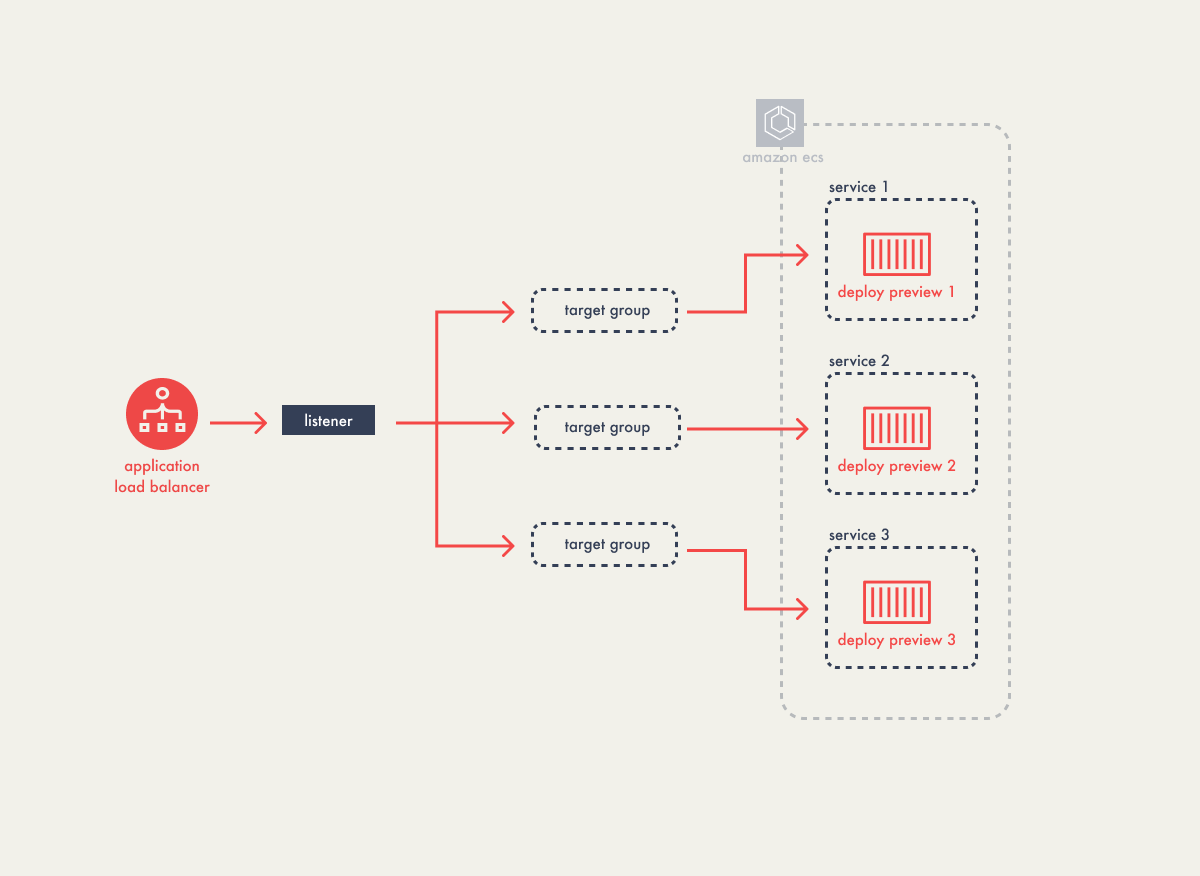
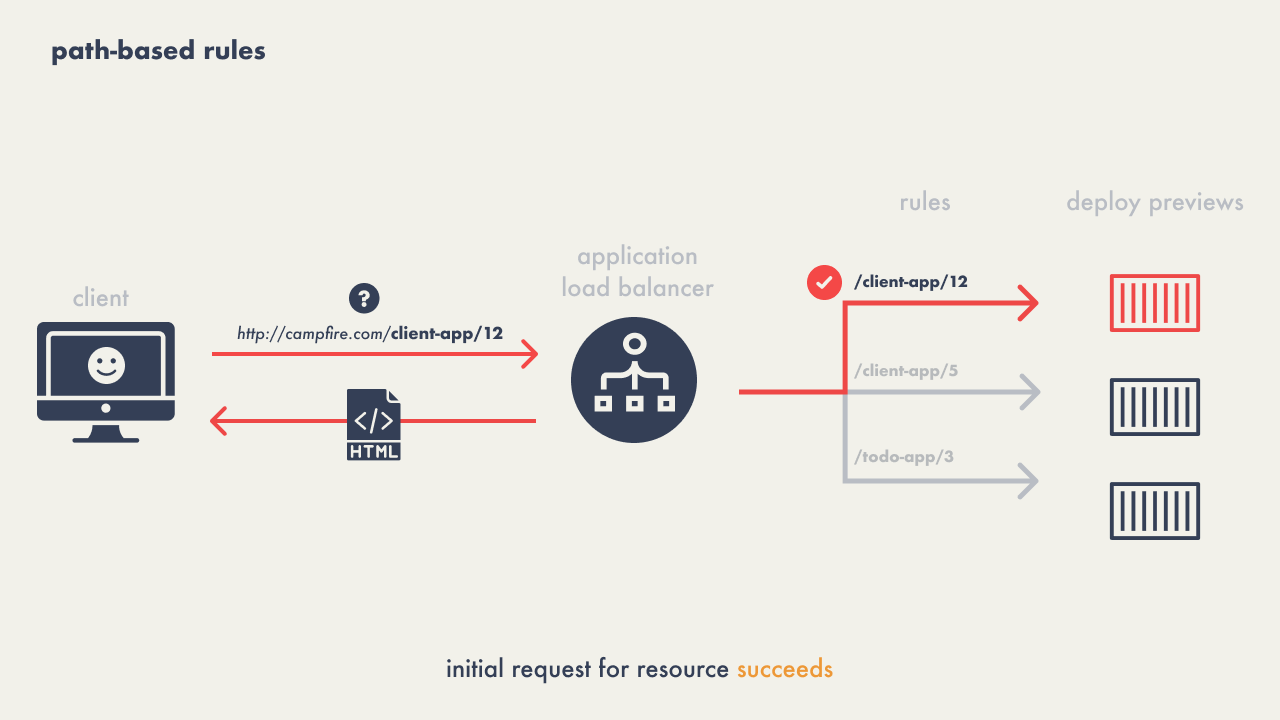
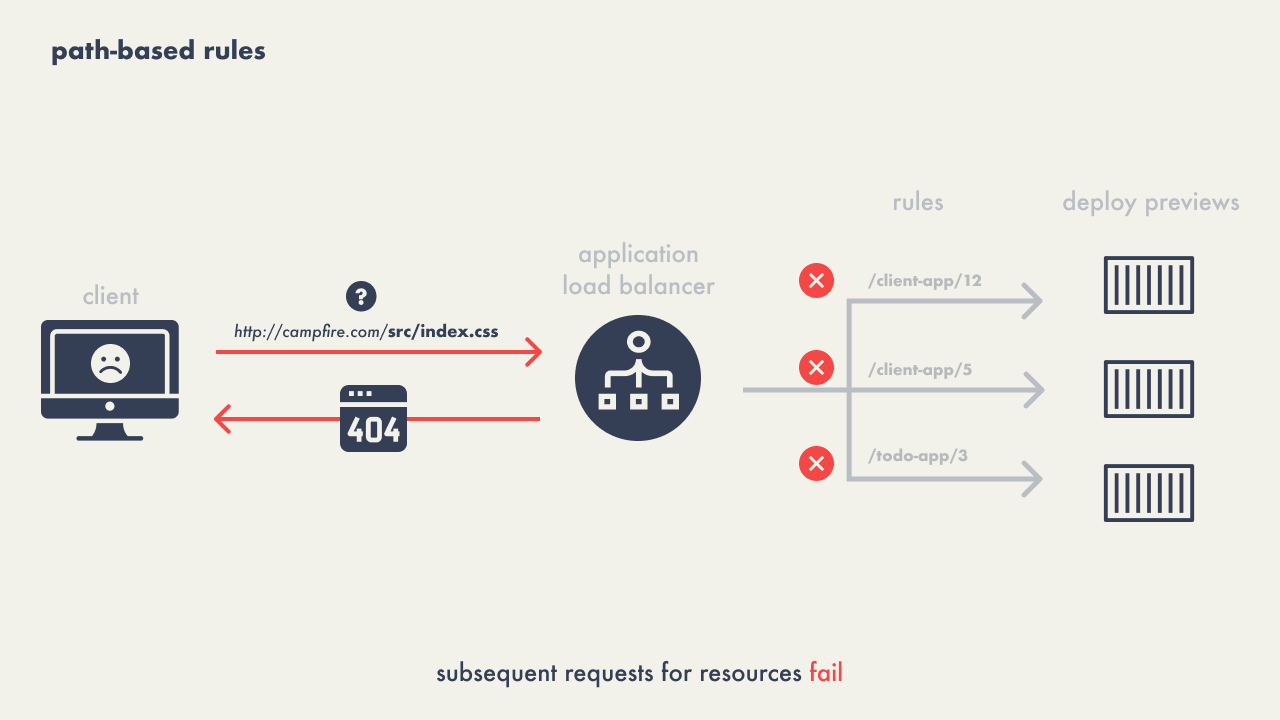
When configuring rules for the load balancer’s listener we first
experimented with path-based rules for routing – directing traffic
to specific services based on URL paths, for example,
"/client-app/12" for accessing the preview of pull
request #12. However, this approach proved inadequate due to 404
errors when browsers requested additional resources not accounted
for in the path-based rules.
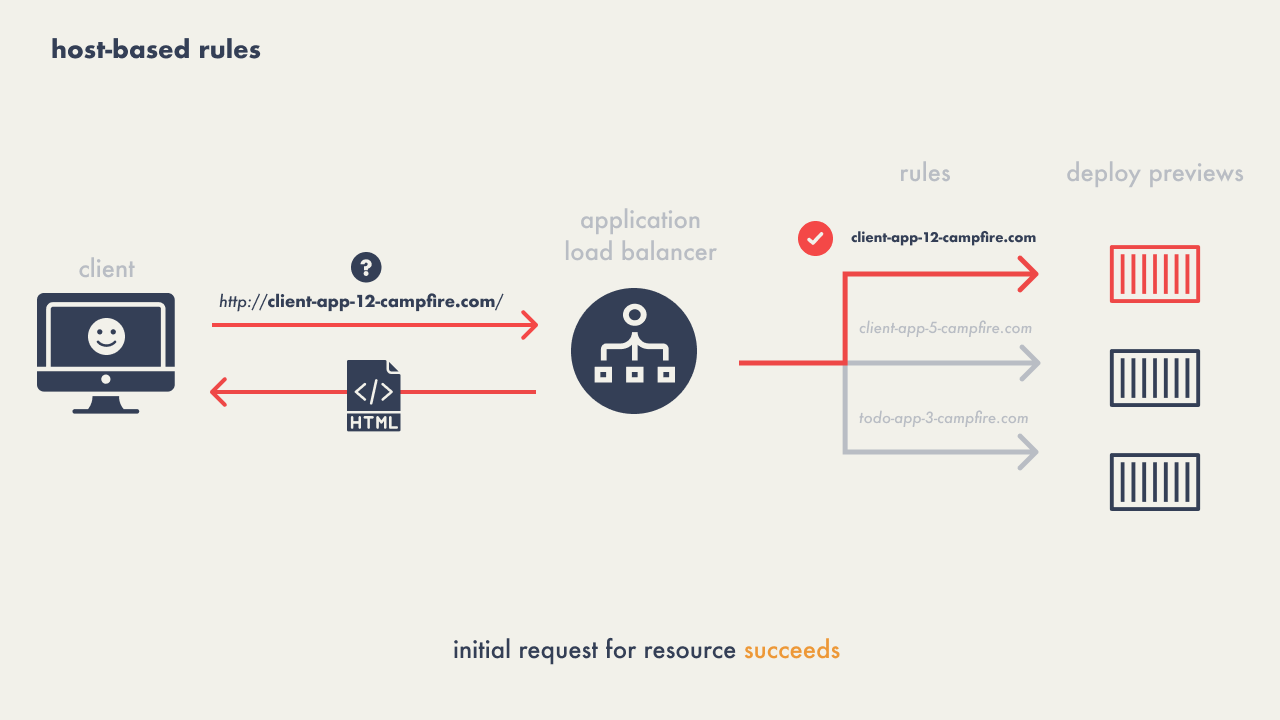
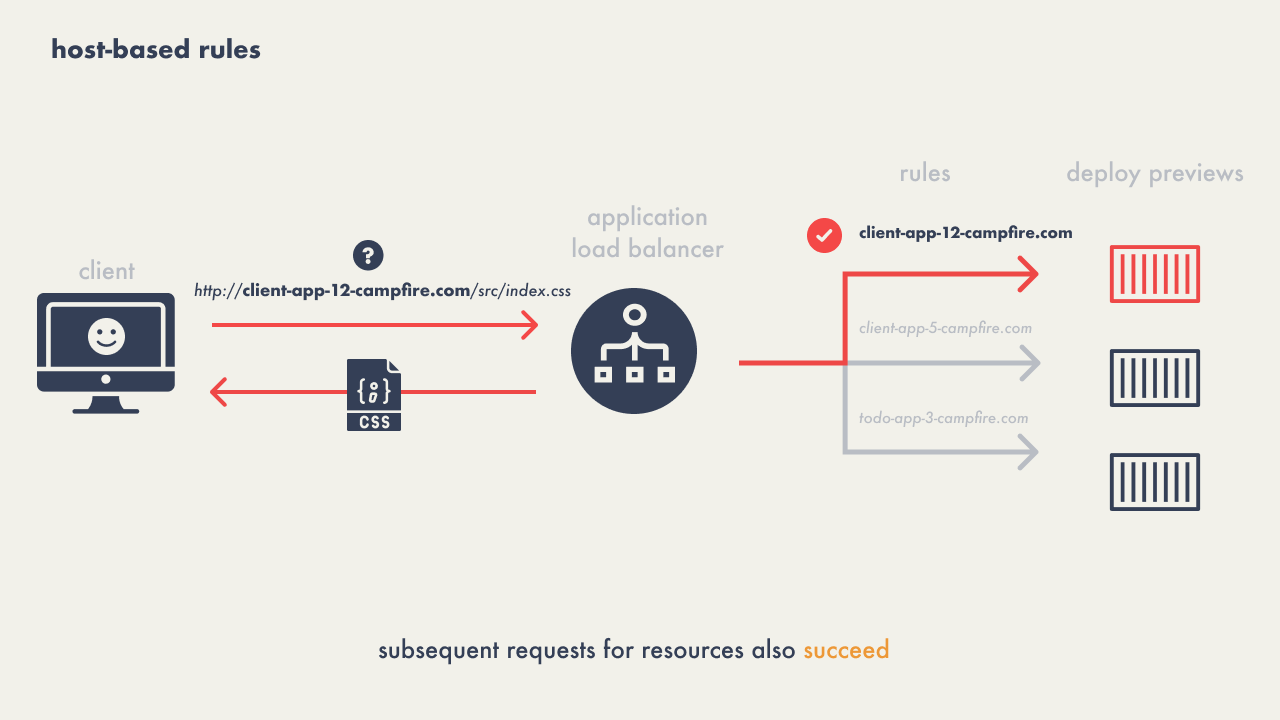
The solution evolved to using host-based routing, where the load
balancer would manage requests to a host like
"client-app-12.preview.campfire.com" as an example,
ensuring all subsequent resource requests for a particular preview
consistently reached the correct service.
This method eliminated the 404 issue as the host-based approach
accurately directed all related traffic to the appropriate deploy
preview environment, regardless of the specific resource being
requested.
5.3 - Feedback Interface
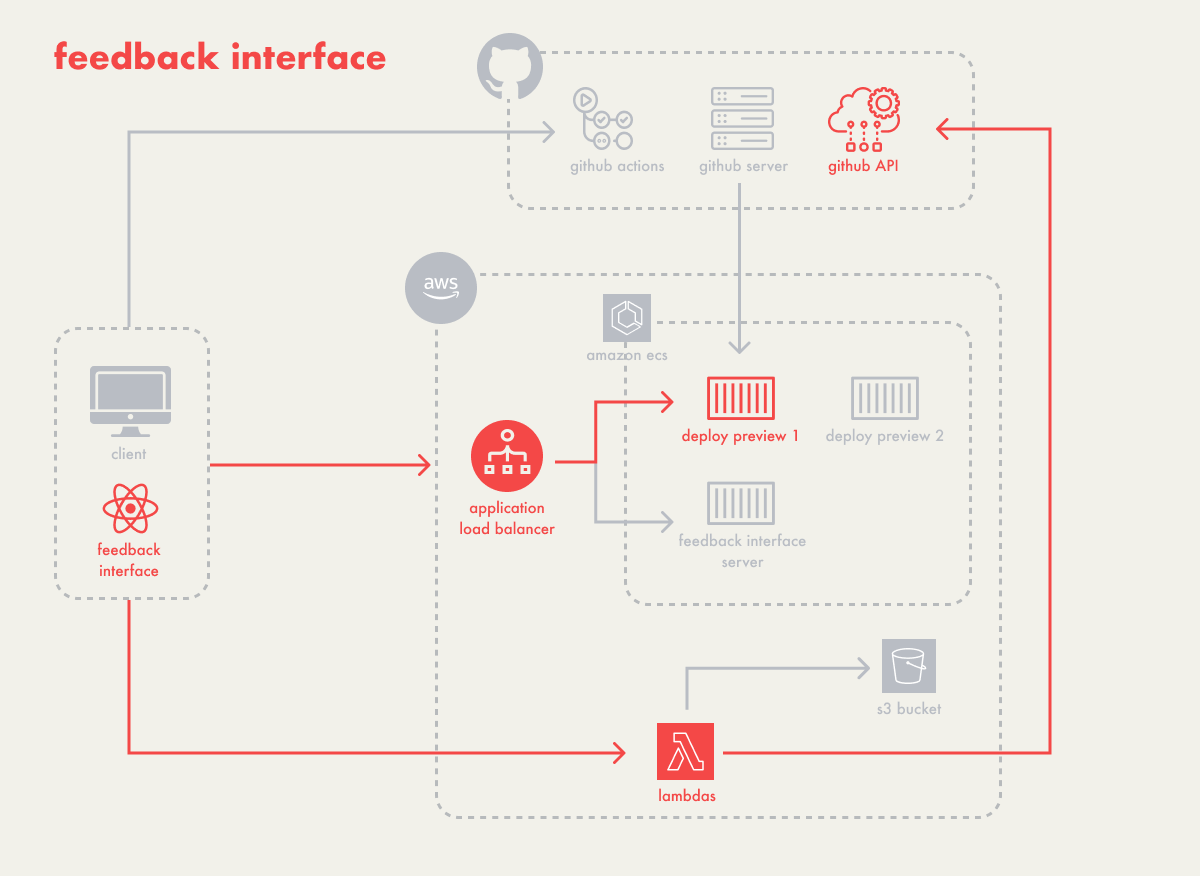
Campfire wanted to design a feedback interface that accomplishes a
few things:
-
integrates with the deploy preview, so that stakeholders don’t
need to switch contexts to add feedback
-
handles comments, since this is the main way stakeholders can
leave feedback
-
allows the user to capture context, for when text comments alone
aren’t enough
We’ll be talking more about why and how we implemented these in
the next few sections, as well as a few challenges we encountered
along the way. Finally, we’ll end with a brief section on our
backend infrastructure.
5.3.1 - Integrating the Deploy Preview with the Feedback Interface
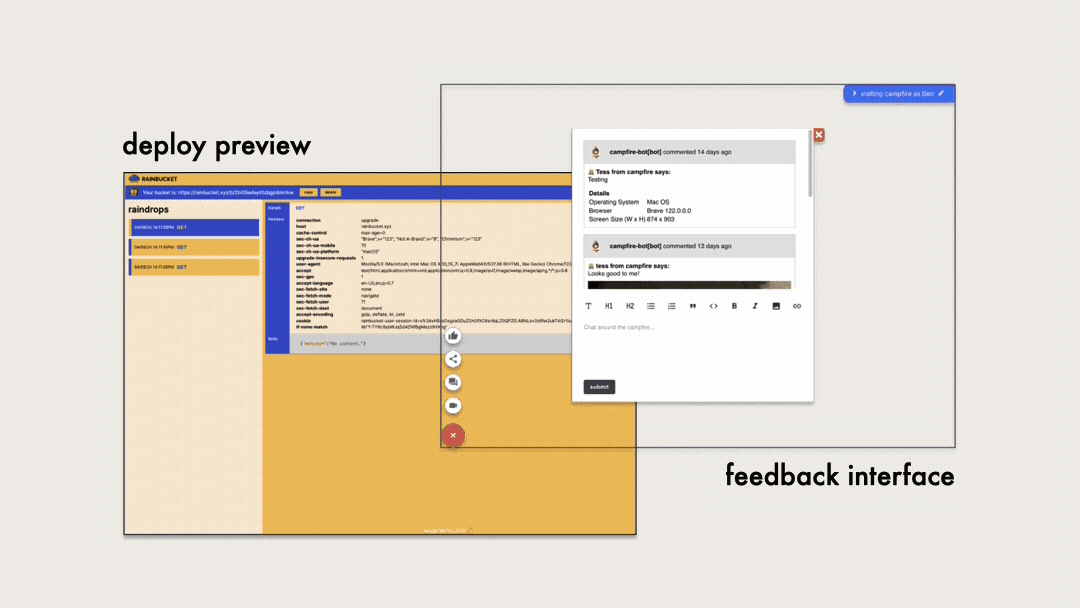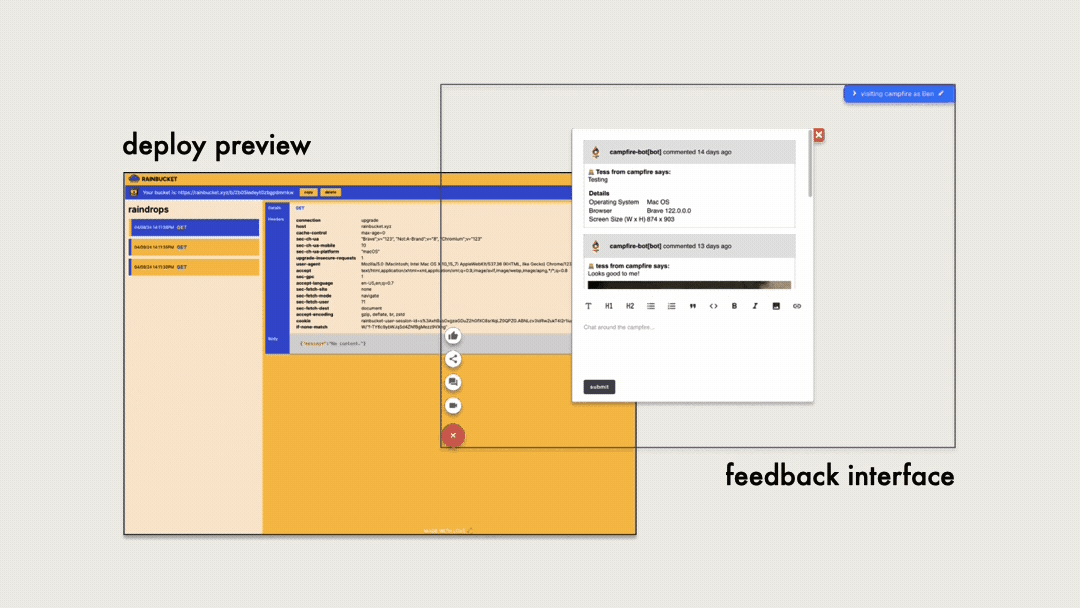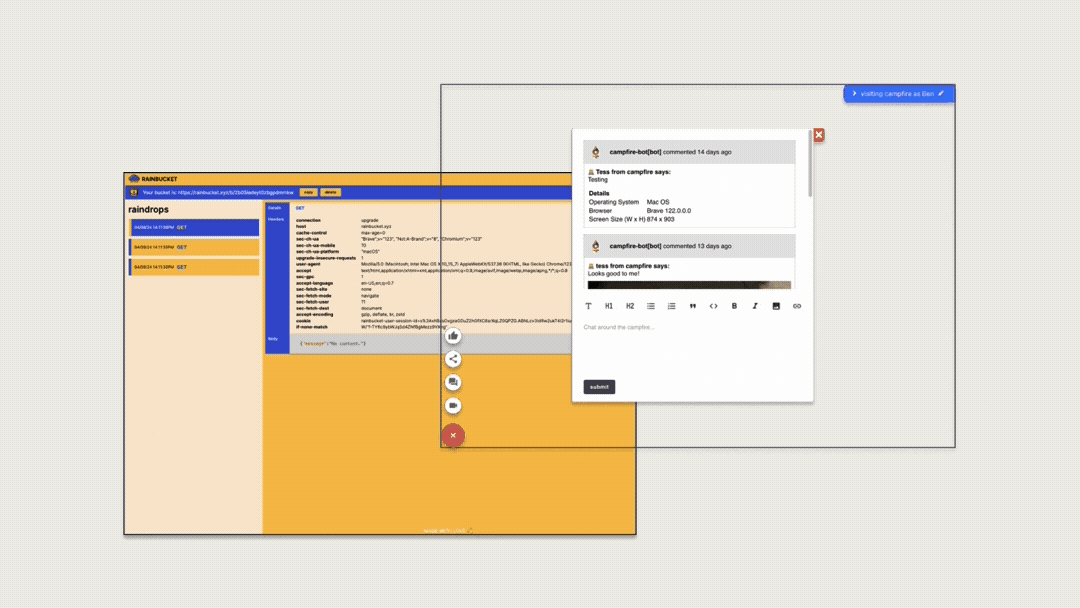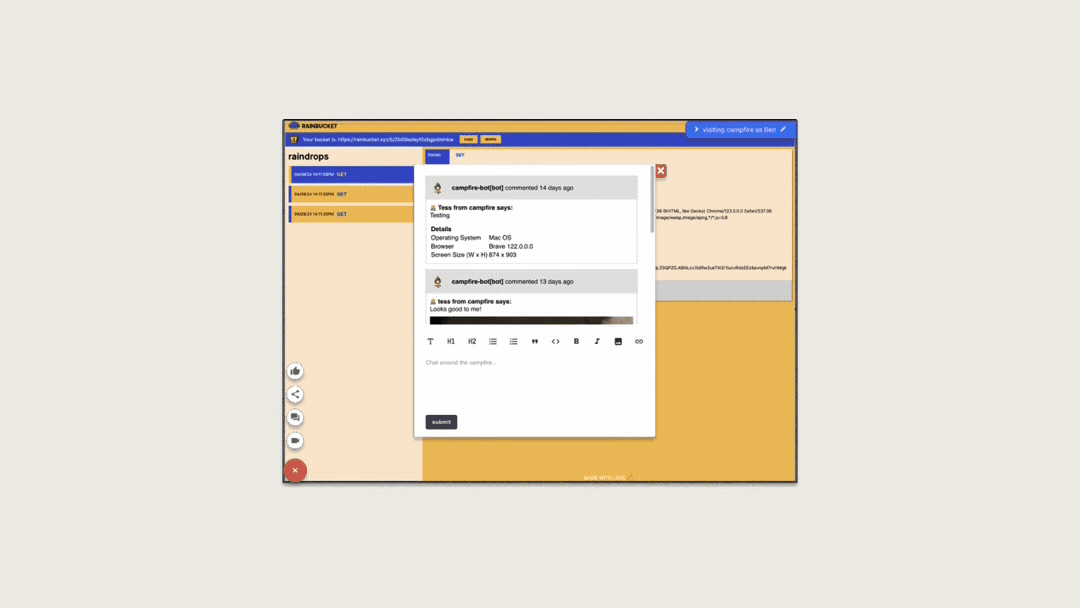
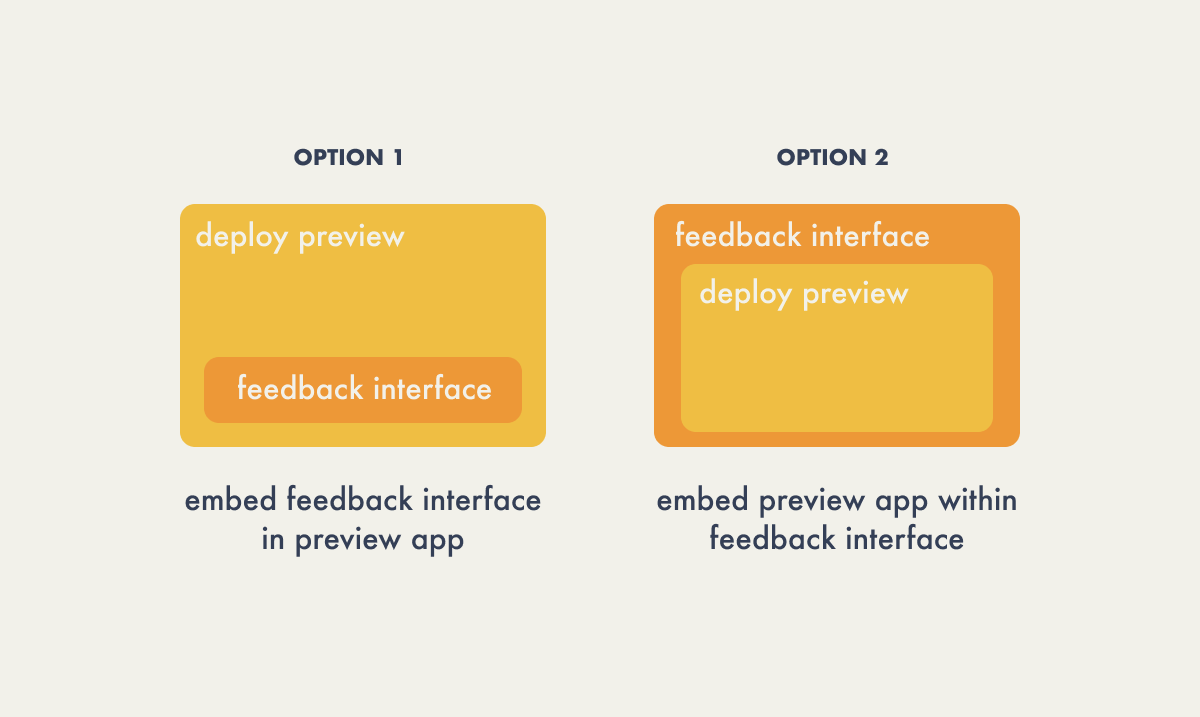
When it came to integrating our feedback interface with our deploy
preview, we had two options:
-
Inject or ask the user to add the feedback interface to their
application – perhaps as a custom web component, script, or
using an iframe.
-
Create a feedback interface application that embeds the deploy
preview within it using an iframe.
The first option involves running a single task, the deploy
preview, with the feedback interface integrated directly into it.
This approach could reduce costs because no additional components
are active when there are no deploy previews. However, it
complicates the user experience by adding an extra step, and may
restrict the types of applications we can support due to the need
to ensure compatibility with various frontend frameworks.
Since the second option would not require any additional work on
the user’s part and would maximize on application compatibility,
we decided to create a separate feedback interface that would
embed the deploy preview. We built a React application with an
iframe that points to the deploy preview.
We opted for the second option, which requires no additional
effort from the user and maximizes application compatibility. To
achieve this, we developed a separate feedback interface,
embedding the deploy preview within an iframe in a React
application.
| Component |
URL |
| Deploy Preview |
client-app-12.preview.campfire.com |
| Feedback Interface |
feedback-interface.campfire.com/client-app/12 |
The user would be given the URL that pointed to the feedback
interface, while the URL generated for the deploy preview would be
used internally by the feedback interface application.
5.3.2 - Comments
Comments allow all stakeholders, including those without technical
expertise or a GitHub account, to actively participate in the
deployment review process enabling detailed feedback and
discussions directly within deploy previews. Comments allow teams
to discuss issues and suggest improvements, fostering an
interactive and collaborative review environment.
We designed Campfire to aggregate comments in both the GitHub
interface and within the deploy preview itself. This dual
visibility ensures that feedback is not lost across platforms and
supports a unified discussion thread that all team members can
follow and contribute to, regardless of where they choose to
interact.
To accomplish this, we needed to retrieve existing comments from
GitHub pull requests and also enable the posting of new comments
from within Campfire. The implementation of this commenting
functionality involved use of GitHub’s API.
GitHub has three options to authorize API requests, although this
can be reduced to less than three depending on the API resource
being accessed. For Campfire to obtain the necessary authorization
in order to push comments from Campfire back to the GitHub pull
request we could use:
- Personal Access Token (requires GitHub account),
- User Access Token (requires GitHub account)
- App Installation Token
Recognizing that not all Campfire users would have a GitHub
account, we chose to utilize GitHub’s App Installation Token for
authorization. This approach enables Campfire to post comments on
behalf of users, allowing feedback added in Campfire to sync with
the pull request. It also permits users who are not registered on
GitHub to contribute their own feedback.
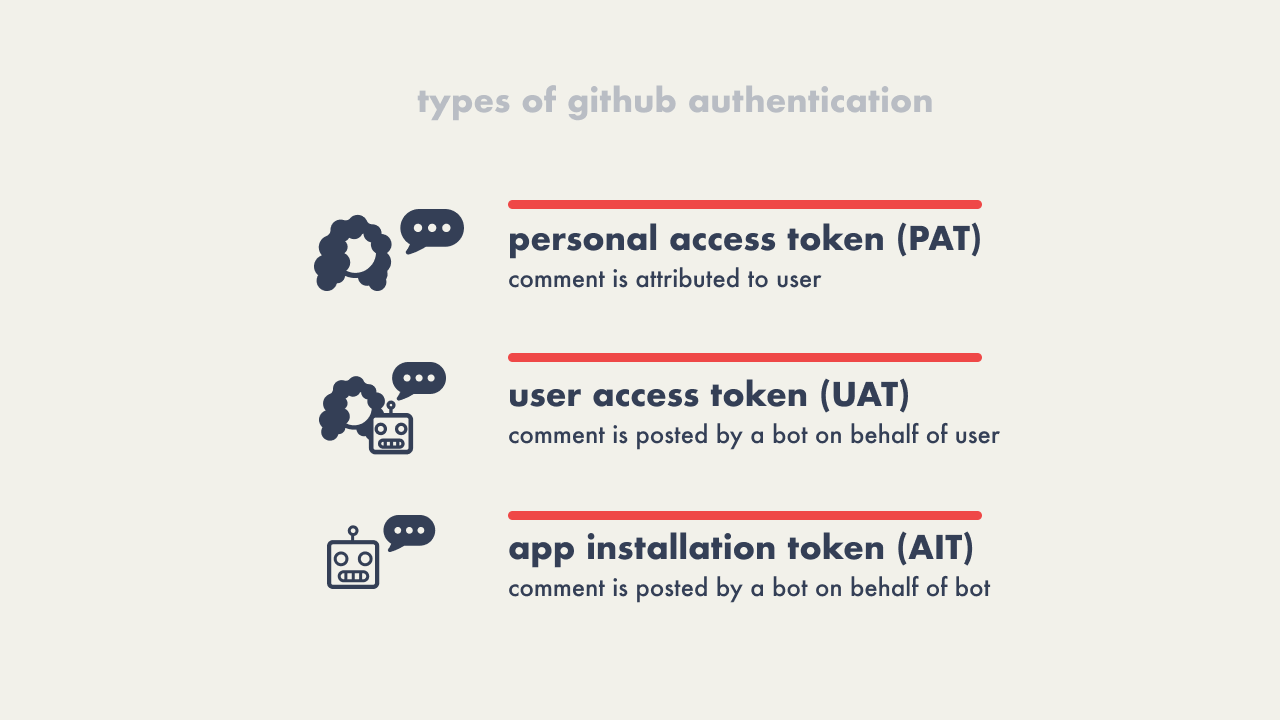
Generating the App Installation Token requires the user or
organization using Campfire to register and install a GitHub App
with configured permissions. Once the app is installed, Campfire
is able to generate the required authorization through its
credentials and cross-post any comments made in Campfire directly
to the pull request.
To avoid exposing sensitive data from the feedback interface, the
GitHub App’s credentials are stored in AWS Secrets Manager. Any
GitHub-related actions taken requires retrieving these credentials
beforehand to authenticate the GitHub App. The following diagram
shows the flow for posting comments:
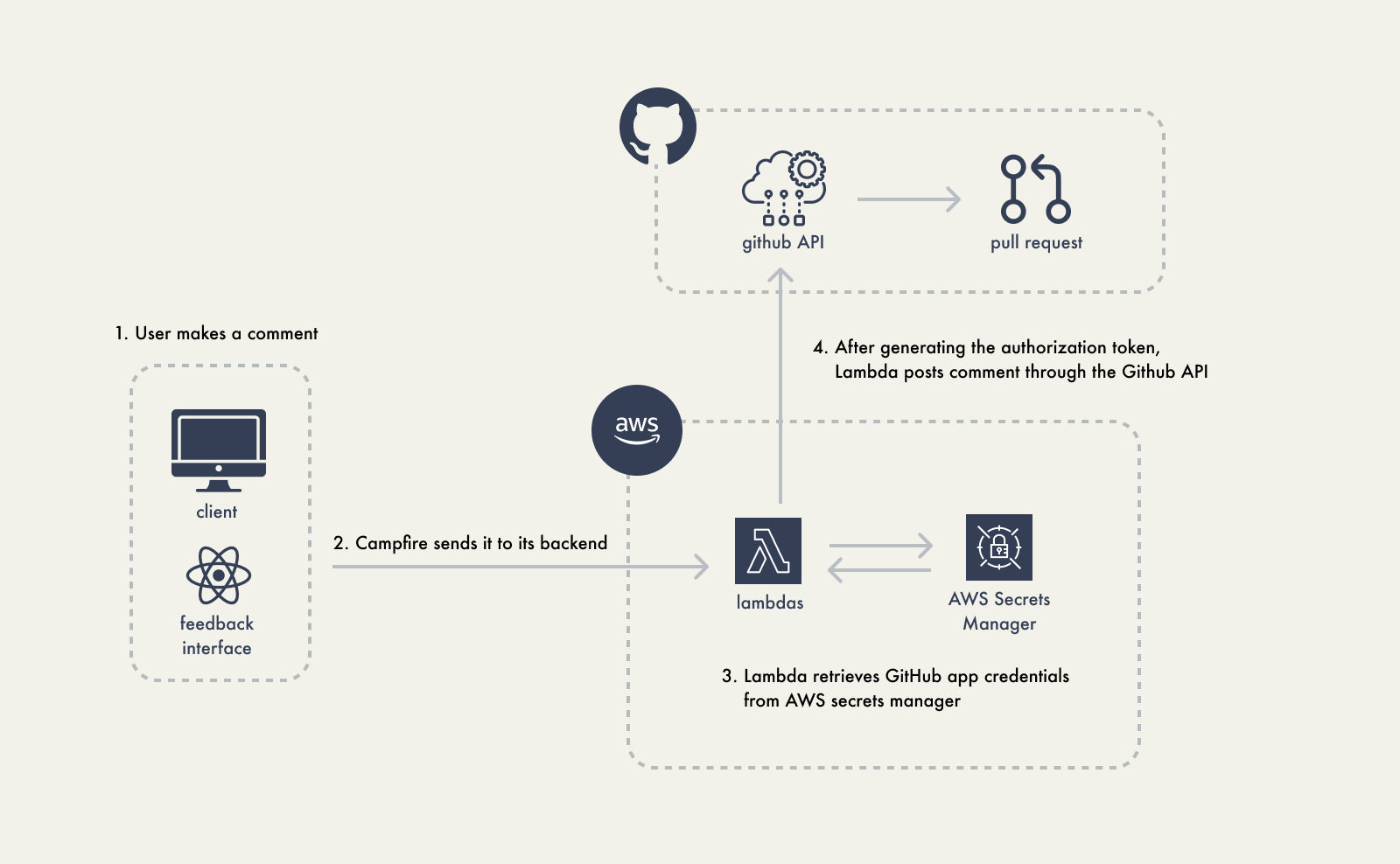
Adding authorization to our requests also benefited our GET
requests by increasing the rate limits and allowing GET requests
to private repos.
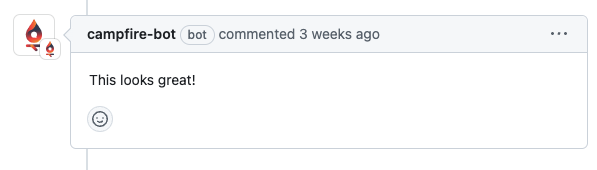
Using our GitHub app to authorize POST requests to the API,
however, also meant that all Campfire user’s comments would be
attributed to the App and not the individuals themselves who were
leaving feedback:
To get around this issue, Campfire displays a welcome screen for
first time users before they are able to view the deploy preview.
The name the user enters is then stored in their browser’s local
storage, ready for use on subsequent visits. The user’s name is
also displayed in the top right corner of the feedback interface
and prefixed to any comments they make through Campfire.
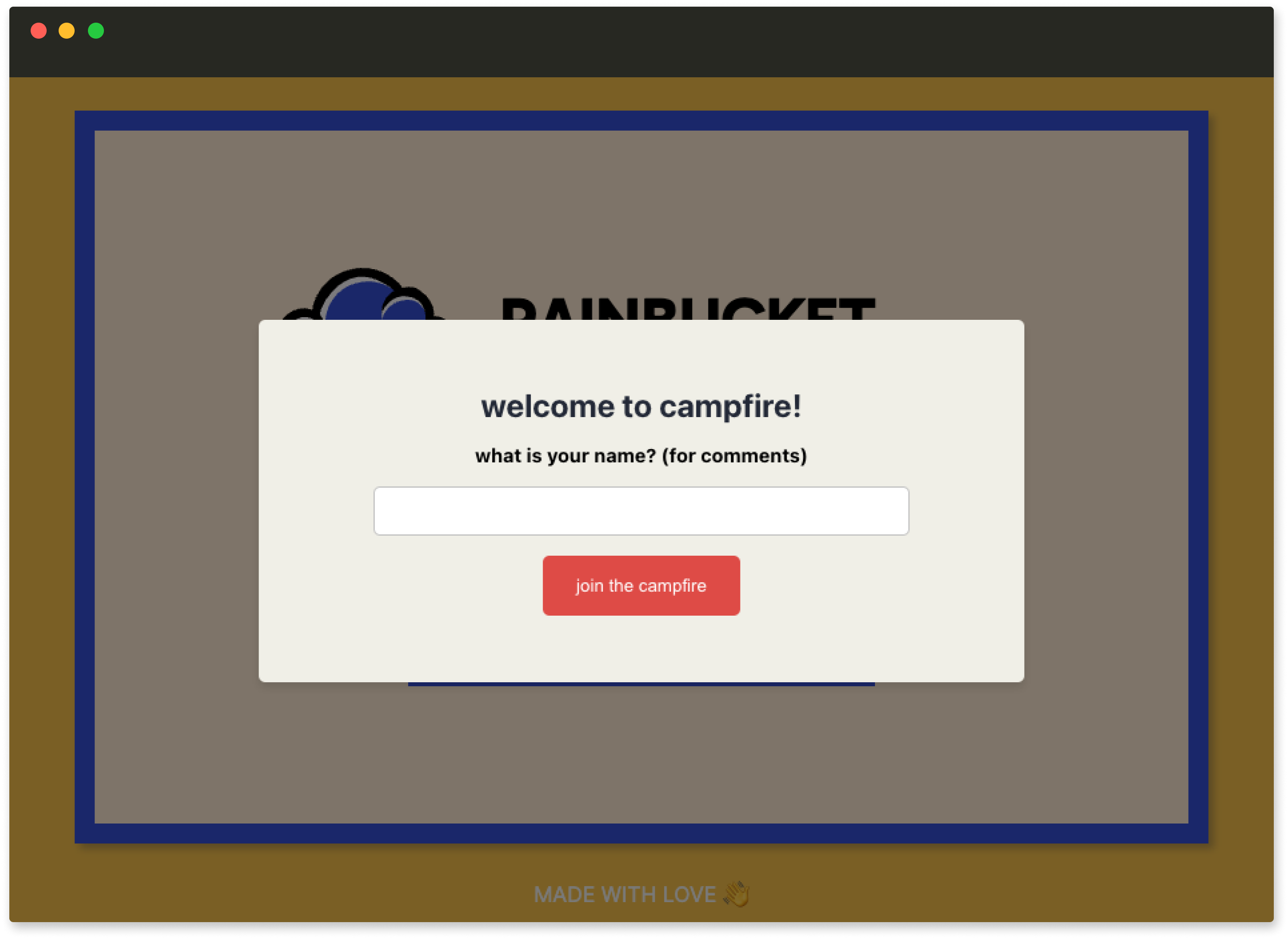
The welcome screen asks the user for their name before they can
interact with the deploy preview.
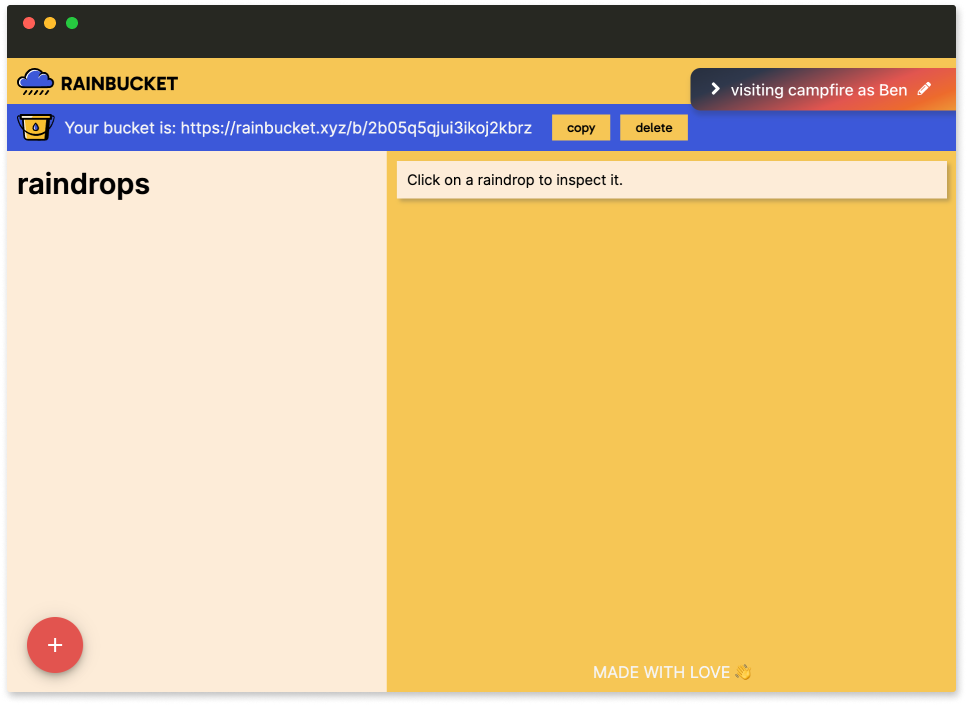
Once they enter their name it’s displayed in the top right.
The tab is collapsible so it’s not in the way.
Comments can now be attributed to the right user:
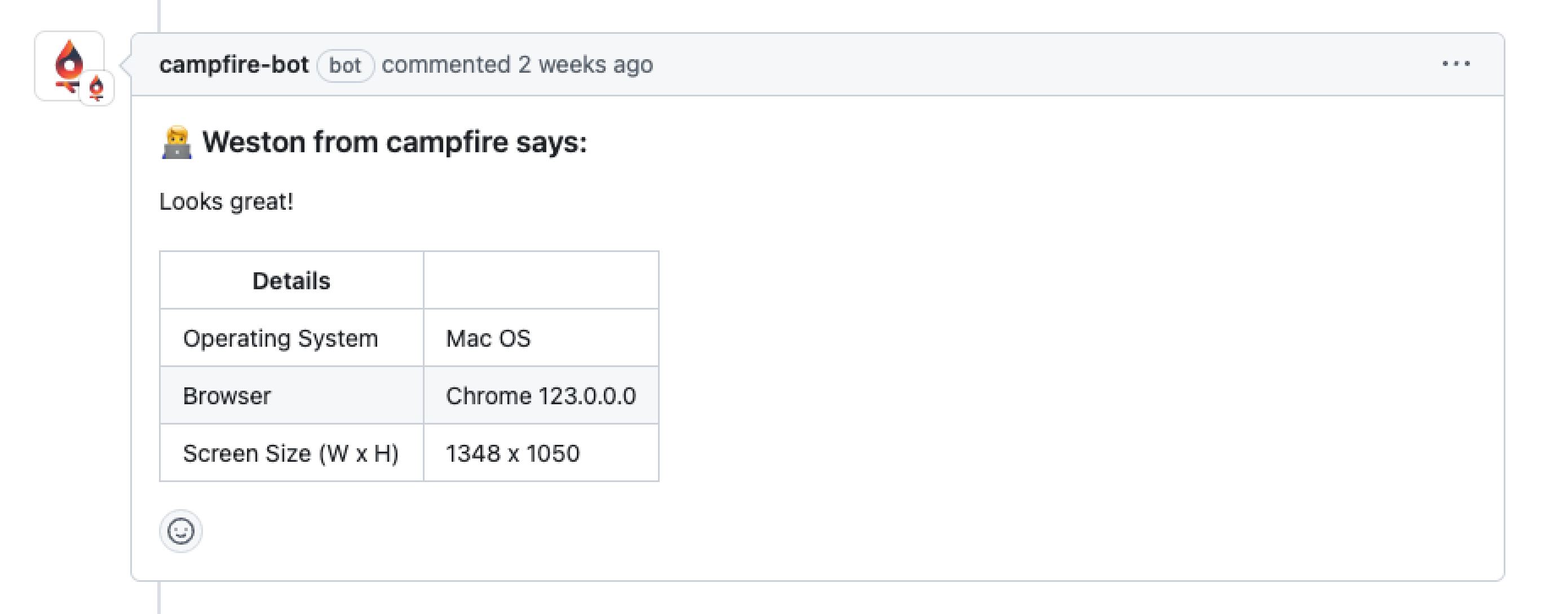
Other context Campfire provides includes some basic information on
the user’s operating system, browser, and screen-size appended to
comments. It may be the case that the UI breaks in certain
browsers, but not others, or when viewed at certain dimensions.
Having the user’s browser stack info enables the engineering team
to more easily replicate the conditions that lead to issues,
thereby fixing any bugs much faster.
5.3.3 - Exploring Screen Capture Solutions
Our team investigated enhancing the Campfire feedback interface
with screen capture functionality to provide richer context for
debugging and user support. The goal was to record interactions to
quickly identify and address issues encountered by developers or
users.
There are a few different approaches to capturing user
interactions:
-
Screenshots - Capture a single moment, useful
for documenting specific issues.
-
Screen recordings - Record a sequence of
actions, providing a video-like overview of user interactions.
-
Session replay - Record all DOM events to
create a detailed playback of user interactions, offering
comprehensive insights into user behaviors and issues.
Initially, we researched the SDKs of third-party tools such as
Loom and Zight, which offer screen recording and screenshot
capabilities. We decided to not use these solutions given that
they’re not open-source or self-hosted, which doesn’t align with
Campfire’s open-source design.
Although screenshots and screen-recording provide visual context,
we sought a more detailed capture of user interactions. Ideally
any captured data should be useful for developers seeking to
understand and accurately replicate issues users face. This led us
to prioritizing implementing a session replay feature, which
records DOM events in detail, facilitating a deeper analysis and
easier replication of issues by developers.
Session replay captures DOM events such as mouse movements,
clicks, scrolls, keystrokes, and changes within the DOM. These
events are stored in an array, and replay involves reconstructing
the user session from these events. This method not only allows
skipping periods of inactivity, enhancing storage efficiency, but
also structures data in a way conducive to further analytics.
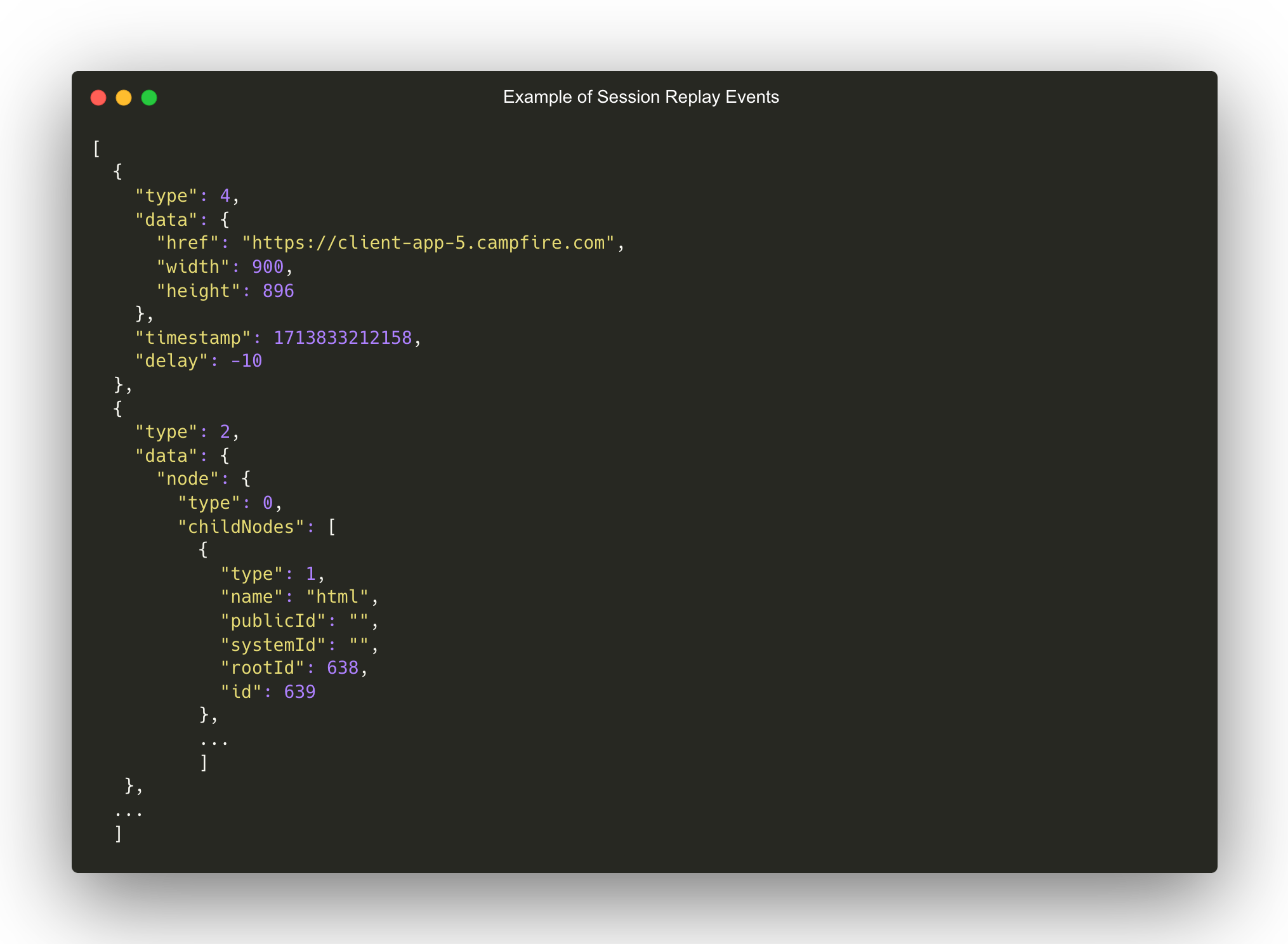
Conversely, screen recordings provide a continuous video capture
of the user's screen, which can include elements outside the
webpage context, like video streams and browser extensions. Screen
recordings can also effortlessly capture content within iframes, a
task challenging for session replay due to security and technical
limitations.
While screen recordings capture more visual information, they lack
the parsability and storage efficiency of session replays. Session
replays, recording only meaningful DOM interactions, avoid
unnecessary data accumulation during inactivity and structure data
for potential analytical use, unlike the less-structured nature of
video files.
After evaluating these options, we concluded that session replay
offered the most advantages for Campfire's needs, aligning with
our goal of providing actionable insights into user behavior while
maintaining efficient data management.
5.3.4 - Implementing Session Replay and SDK
Choosing to implement a session replay feature was not without its
complications. Because a session replay is by default not able to
record events occurring within an iframe, we had some additional
work ahead of us.
We chose the rrweb library to implement this feature due to its
ease of use and open-source nature. Cross-origin policies and
browser security measures prohibit session replay libraries such
as rrweb from accessing the contents of an iframe that are hosted
on different domains. For Campfire, this meant we were unable to
record interactions from the client’s application because the
deploy preview domain and feedback interface domain were not the
same.
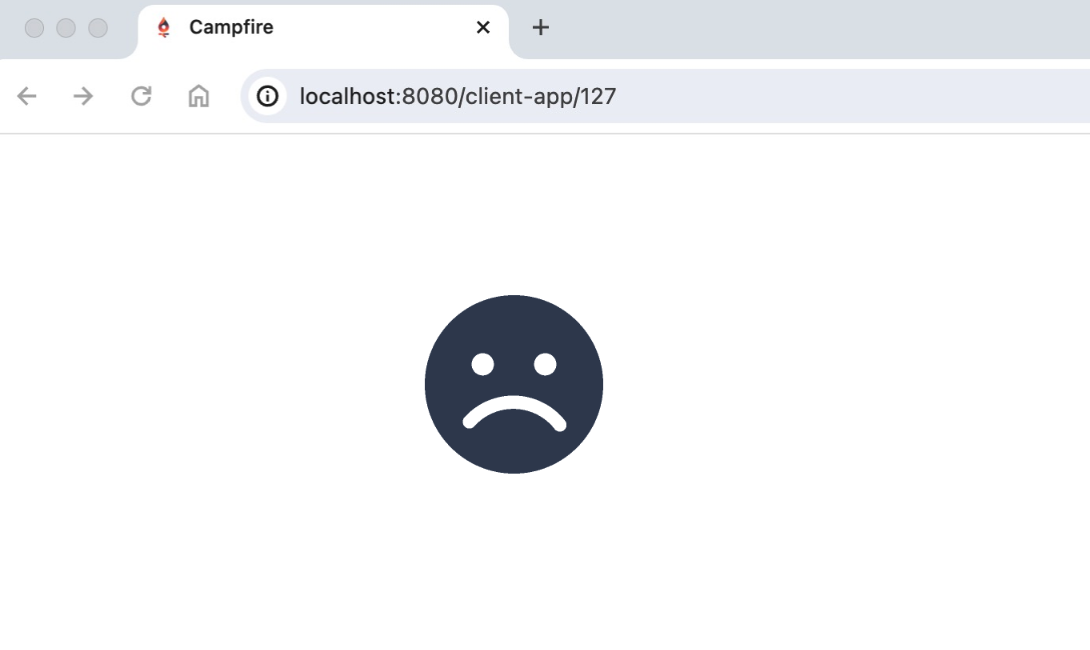
The following gif shows the blank screen that would result:

In situations where developers have ownership of both the parent
application and the child application, rrweb recommends embedding
their library components into both applications. All recorded user
interactions in the child application can then be sent to the
parent application.
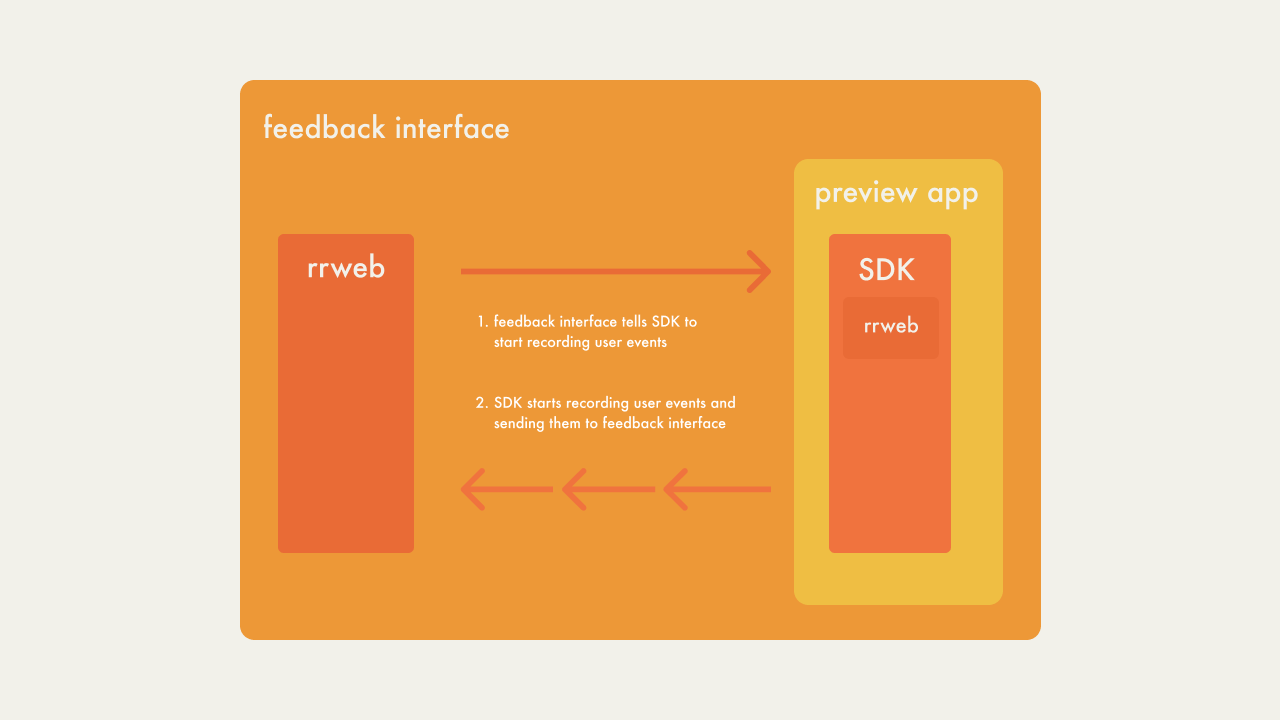
The diagram below illustrates this solution in terms of Campfire’s
use-case. Here the feedback interface is the parent application
and the deploy preview (preview app) is the child application.
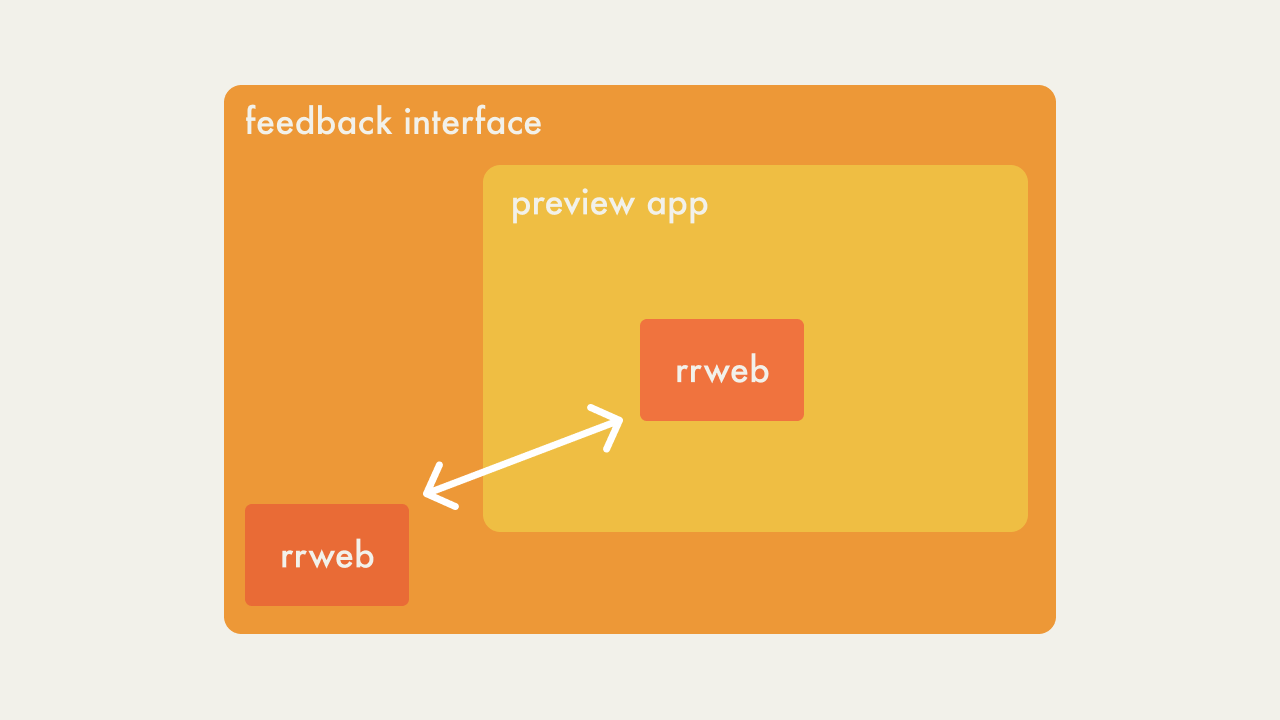
Implementing rrweb's solution to successfully display iframes in
recordings required having rrweb’s component embedded in the
client application. This presented an additional prerequisite for
the user: the rrweb component (or an SDK) must be embedded into
the application in order for the session replay feature to
function properly. We initially dismissed this option as one of
our priorities in developing Campfire was to have as few
prerequisites for our users as possible.
The second option to rrweb’s solution was to programmatically
inject the rrweb component into the embedded application. This
removed the prerequisite for users to manually embed the component
themselves. However, this idea was later deemed unviable due to
security measures enforced by browsers. The same cross-origin
policies that restricted rrweb from directly recording iframes
also restricted the parent application from accessing the contents
of the iframe.This meant the feedback interface could not
manipulate the DOM of the iframe and inject the rrweb component.

The third option was for the client application to use special
response headers when being retrieved from the feedback interface.
In the HTTP request/response lifecycle, the
Content-Security-Policy response header can be used to authorize
certain origins to access the requested resource, in this case the
client application, within iframes. This meant the feedback
interface could be whitelisted and allowed to manipulate the DOM
of the embedded client application.
While this approach appeared to be a practical solution, using
special response headers would require additional AWS services to
append the response heads to resources. AWS’s Application Load
Balancer does not provide a mechanism for adding response headers.
AWS Cloudfront, on the other hand, provides the capabilities to do
so. To avoid adding additional complexity to our AWS
infrastructure, we did not choose this approach.
After considering our possible solutions and their tradeoffs, we
decided the simplest approach would be to create our own SDK and
require clients to embed the SDK into their applications. The SDK
abstracts away the rrweb library component and is responsible for
transmitting recorded user interactions back to the feedback
interface.
Although the SDK adds an additional prerequisite for our users, we
believed it was the most straightforward option for our first
iteration of Campfire. An advantage of building an SDK is we can
continue to build onto the SDK in the future to add new features
to the feedback interface. Features that we had previously decided
against due to the lack of inter-iframe communication can now be
implemented with the addition of the SDK.
5.3.6 - Handling Ad Blocker Interference
After incorporating the rrweb library for session replay into our
Campfire application, we encountered another issue: the entire
Campfire app failed to load for users with ad-blocking extensions
active in their browsers. This problem was traced back to rrweb
being integrated into several of our React components, which are
interconnected. When rrweb was blocked by an ad blocker, it led to
a cascading failure, preventing the entire application from
loading, not just the session replay feature.
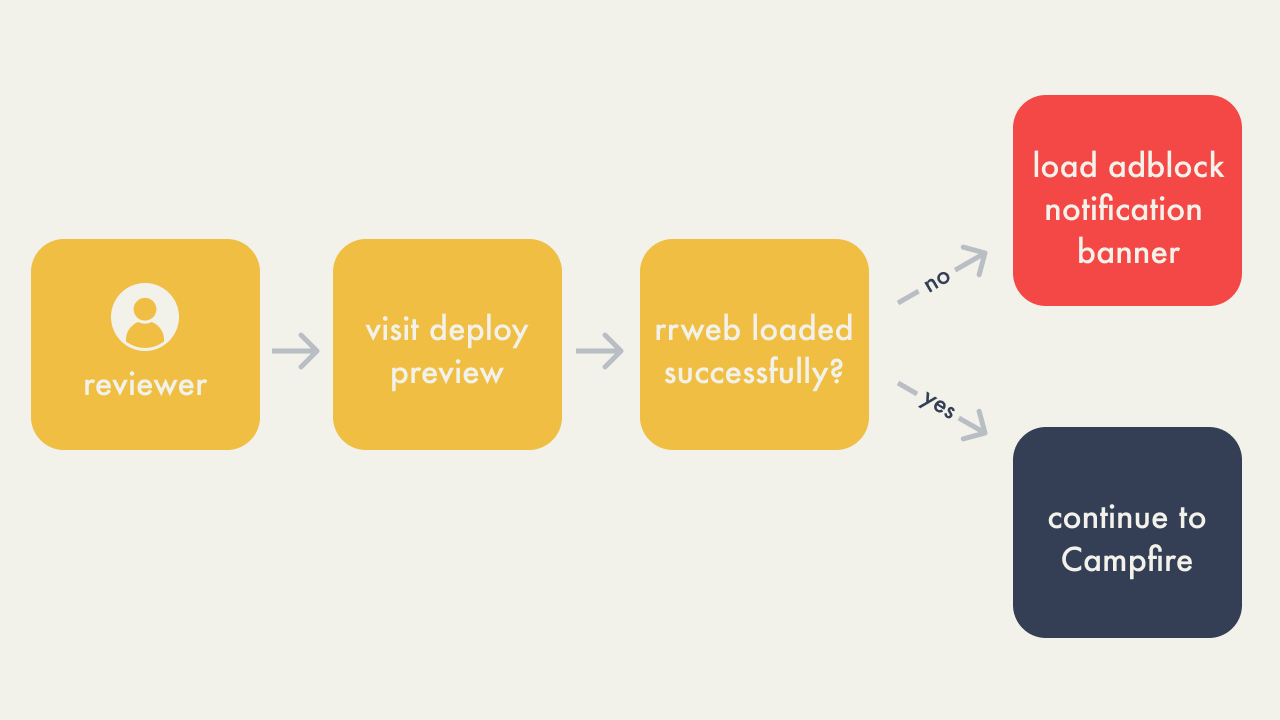
To address this, instead of identifying and managing individual
ad-blocking extensions, we focused on detecting whether the rrweb
functionality was obstructed. If rrweb failed to load, we
implemented a system to inform the user through a notification
banner, advising them to disable their ad blocker to access
Campfire.
Implementing this solution involved exploring dynamic component
and module loading in React. By adopting dynamic imports, we were
able to conditionally load rrweb components, ensuring that even if
these components failed to load due to an ad blocker, the rest of
the application would remain functional. This approach also
allowed us to display a banner alerting users of the need to
disable their ad blockers.
5.3.7 - Serverless Backend
At this point, Campfire needed a backend to use GitHub’s API and
to use the AWS SDK. Authenticated calls to GitHub's API were for
retrieving and posting comments to pull requests, while the AWS
SDK was needed to store user generated session replay data.
Initially two approaches were considered for our backend
infrastructure:
- traditional server-based backend
- a serverless architecture
A traditional backend setup would involve using a server, for
example an Express application, paired with a web server, like
Nginx, to manage API routing. This type of set-up would have the
benefit of avoiding cold starts that are the result of using a
serverless architecture. The trade-off is that the user would have
to pay the costs of having a server running continuously, even if
there are little to no requests being handled. Since deploy
previews don’t necessarily need the speed that comes with avoiding
cold starts, we thought it best to maximize cost-efficiency.
We opted for a serverless approach using AWS Lambda, a computing
service that allows you to execute code without provisioning or
managing servers. Using an API Gateway with Lambda integration did
not require an additional service to be hosted for the backend.
However, it did require the incorporation of several new
resources, primarily the API Gateway and Lambda functions. While
this choice added additional complexity to Campfire’s
architecture, the services we chose to use are far less expensive
than having multiple ECS services running on a cluster on the
user’s account.
5.4 - Data Storage
The primary data that Campfire needed to store was session replay
data, which took the form of arrays of event objects. For storage,
we considered AWS Elastic File System (EFS) and AWS S3 buckets
(S3), both accessible via lambdas and capable of being shared
across all containers if needed.
Although both EFS and S3 would be able to support this data, they
have slightly different use cases. EFS is meant to be a shared
file system among multiple containers, and works well for when you
need to structure your data in a hierarchical manner with nested
folders and files. It’s primarily meant to be used internally by
those instances.
S3 is an object storage system that allows you store any type of
data in an unstructured way, and lets you retrieve it using a
unique identifier. It’s useful as a data store for objects that
need to be accessed over the internet. With S3, access to stored
objects could be available outside the containerized instances.
Since Campfire didn’t necessarily need a shared file system, but
rather a place to store discrete pieces of data to be retrieved
later, S3 seemed a better fit. It also gave two more advantages:
-
We could store our files for our Lambda functions in the S3
bucket, which Cloud Formation could then pull from during set-up
-
Opens up possibility for later storing user uploaded
screenshots, which, because of the external nature of S3 items,
would make the images available not just within the feedback
interface, but also on GitHub pull-requests
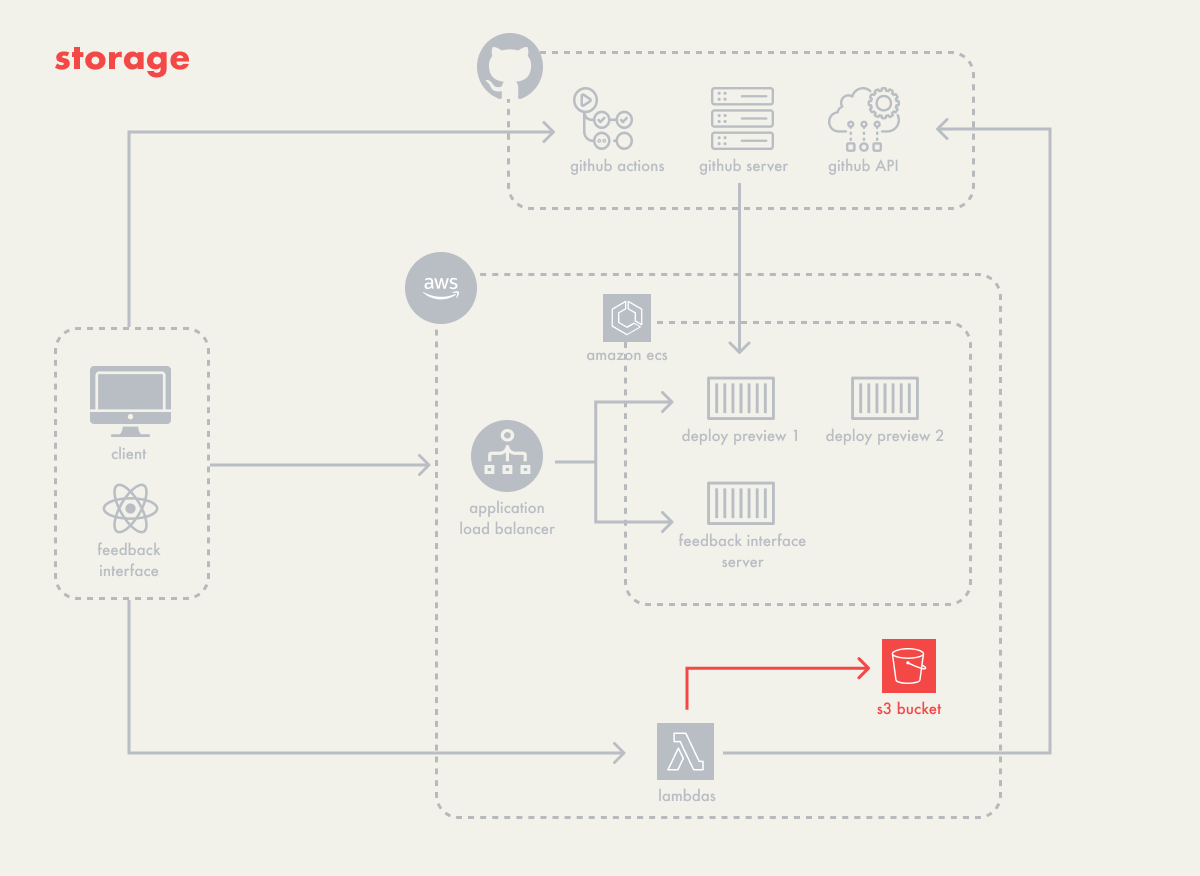
The following diagram shows our architecture as a whole:
6 - Future Work
6.1 - CSS Editor
Integrating a CSS Editor into Campfire’s feedback interface would
allow users to suggest CSS modifications directly within the
preview environment. This feature would enable more detailed
visual collaboration on styling changes and improve the process of
refining the UI/UX. Proposed CSS changes could then be
automatically formatted into code snippets and attached to the
corresponding pull request, facilitating a smoother review and
integration workflow.
6.2 - Screenshots
Introducing a screenshot feature would enable users to capture and
share specific moments or layouts from their deploy preview
without having to record an entire session replay. This would be
particularly useful for visually documenting issues or
highlighting design elements, providing a quick and clear
reference point in discussions. Additionally, images can be posted
to GitHub discussions directly instead of having a session replay
link that takes users back to their deploy preview. .
6.3 - GitHub User Authorization
Enhancing Campfire with optional GitHub user authorization would
allow users to interact with the feedback interface directly. This
would ensure that comments and feedback are accurately attributed,
enhancing traceability and accountability in the collaboration
process.
6.4 - Reduce Costs
In the future, we also want to explore ways to cut costs, possibly
using web components or other techniques. Our current setup has
the client app and feedback interface on separate clusters, which
can be inefficient. For example, the feedback interface's cluster
runs non-stop, costing money even without active deploy previews.
A better approach might be to merge the feedback interface with
the client app before deployment. This could be done by injecting
code or using web components, which would allow both parts to run
on the same cluster, saving resources and money.
Additionally, we may consider implementing a scaling strategy
where the system could automatically scale down to zero in periods
of inactivity. This approach would reduce the cluster to minimal
operational status, effectively cutting costs by not running
unnecessary resources.